あけましておめでとうございます。←
2020も頑張りましょう。
今回は表題の通り、画像系深層学習の判断根拠手法について、近年人気のある手法「Grad-CAM」と、その改良版「Grad-CAM++」、さらに去年論文発表されたばかりの「Score-CAM」を、TensorFlow/Kerasで実装・比較してみます。
データセットはKaggleのデータセットを使い、カーネルノートブックのGPUを使って深層学習させましたので、全コードはそちらを参照ください。
kaggle notebook: https://www.kaggle.com/itoeiji/visual-explanations-gradcam-gradcam-scorecam
一応ノートブックをアウトプットしてGitにも同じものをあげています。
判断根拠の可視化について
深層学習は、特に画像認識分野で優れたパフォーマンスを実現する可能性があります。
しかし、それらは直感的でなく、理解可能なコンポーネントへの分解も難しいため、解釈可能性が低くなりがちです。
そのため、近年では、深層学習モデルが、画像のどこにフォーカスして予測をしたのかといった、判断根拠を視覚化する方法が研究されています。
以下は、最近人気のあるGrad-CAMの視覚化の例です。(Grad-CAM論文抜粋)

判断根拠の可視化のメリットは主に2つあります。
1つは、先のような解釈可能性の低さを改善し、モデルの透明性を向上できることです。
これにより、モデルの予測ロジックを言語化でき、妥当性を評価できるため、実社会の特に責任の伴う場面に適用しやすくなる可能性があります。
もう1つは、学習データのバイアスに気づくことができることです。
上記の視覚化例は論文から抜粋したもので、「ドクター」と「ナース」を分類するモデルの可視化例ですが、真ん中列は、学習データに、「ドクター」は男性、「ナース」は女性として、バイアスがかかったデータを学習させてしまっていたために、人の顔や髪の部分を見て、どちらも「ナース」と予測してしまっている例です。
これを性別のバイアスを学習データから取り除いた結果、人が持っている医療器具を注視するようなった(右列)という例になります。
データセット・モデルアーキテクチャ
では、実装例を見ていきます。
実装のために、画像分類用のデータセットとして、以下のデータセットを利用します。
Intel Image Classification: https://www.kaggle.com/puneet6060/intel-image-classification
下記6クラスにラベル付されている画像データセットです。
- 建物(buildings)
- 森(forest)
- 雪山(glacier)
- 山(mountain)
- 海(sea)
- ストリート(street)
以下のように、各クラスについて、枚数、比率、サンプル画像を何枚か表示してみました。
いずれも同じくらいの比率で、2,000枚ほど格納されているようです。
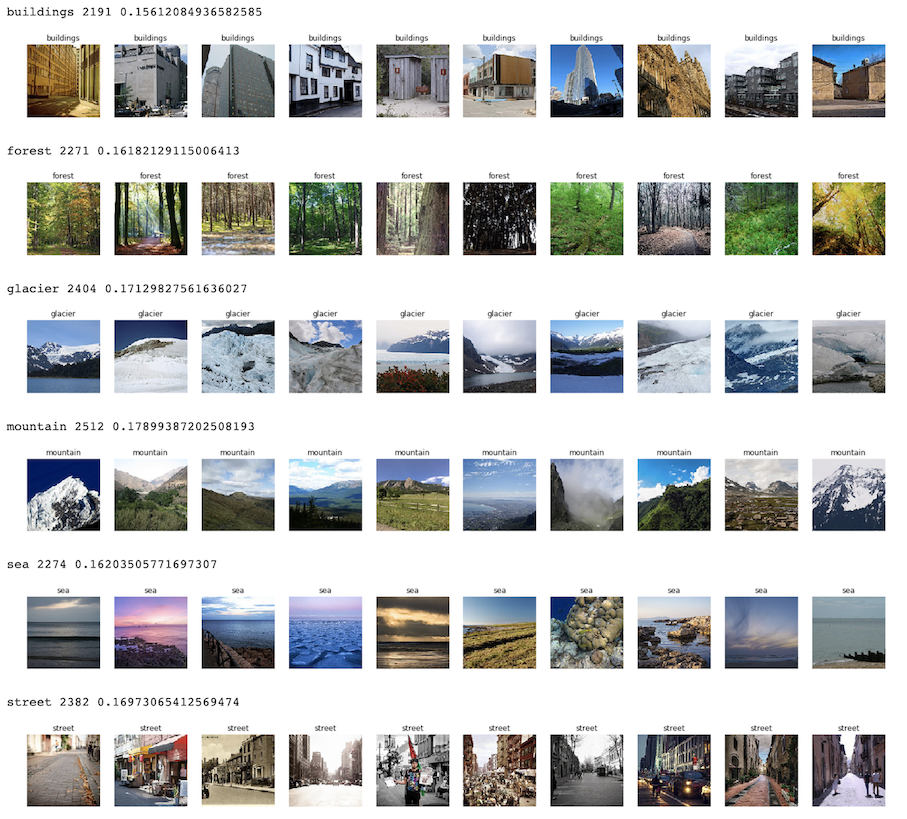
この時点で、gracierとmountainは分類が難しそうなのがわかります。
枚数も少なめなので、モデルのアーキテクチャは、学習済みResNet50のファインチューニングでモデルを作ってみます。
学習はオーグメンテーションを行うようにイテレータを作成しました。
## to image data generator
datagen_train = ImageDataGenerator(
preprocessing_function=preprocess_input, # image preprocessing function
rotation_range=30, # randomly rotate images in the range
zoom_range=0.1, # Randomly zoom image
width_shift_range=0.1, # randomly shift images horizontally
height_shift_range=0.1, # randomly shift images vertically
horizontal_flip=True, # randomly flip images horizontally
vertical_flip=False, # randomly flip images vertically
)
datagen_test = ImageDataGenerator(
preprocessing_function=preprocess_input, # image preprocessing function
)
def build_model():
"""build model function"""
# Resnet
input_tensor = Input(shape=(W, H, 3)) # To change input shape
resnet50 = ResNet50(
include_top=False, # To change output shape
weights='imagenet', # Use pre-trained model
input_tensor=input_tensor, # Change input shape for this task
)
# fc layer
top_model = Sequential()
top_model.add(GlobalAveragePooling2D()) # Add GAP for cam
top_model.add(Dense(n_classes, activation='softmax')) # Change output shape for this task
# model
model = Model(input=resnet50.input, output=top_model(resnet50.output))
# frozen weights
for layer in model.layers[:-10]:
layer.trainable = False or isinstance(layer, BatchNormalization) # If Batch Normalization layer, it should be trainable
# compile
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
return model
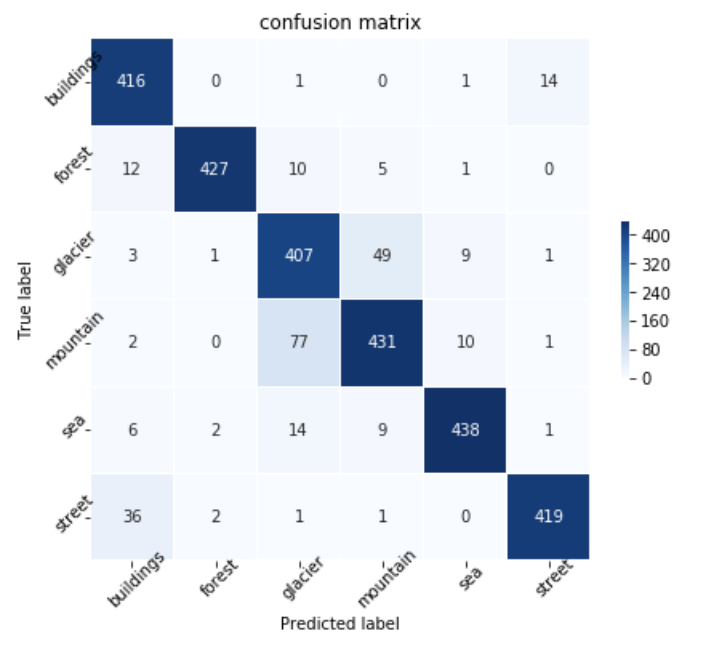
こちらで学習をさせてみたところ、以下のように90%ほどの精度となりました。
やはりglacierとmountainは間違えやすい傾向にありそうです。
## finetuning
history = model.fit_generator(
datagen_train.flow(x_train, y_train, batch_size=32),
epochs=5,
validation_data=datagen_test.flow(x_test, y_test, batch_size=32),
)
Epoch 1/5 351/351 [==============================] - 75s 214ms/step - loss: 0.5013 - accuracy: 0.8232 - val_loss: 0.5438 - val_accuracy: 0.8682 Epoch 2/5 351/351 [==============================] - 53s 151ms/step - loss: 0.3160 - accuracy: 0.8848 - val_loss: 0.0736 - val_accuracy: 0.8985 Epoch 3/5 351/351 [==============================] - 54s 154ms/step - loss: 0.2700 - accuracy: 0.9047 - val_loss: 0.6587 - val_accuracy: 0.9013 Epoch 4/5 351/351 [==============================] - 53s 152ms/step - loss: 0.2428 - accuracy: 0.9124 - val_loss: 0.2880 - val_accuracy: 0.9145 Epoch 5/5 351/351 [==============================] - 53s 151ms/step - loss: 0.2244 - accuracy: 0.9189 - val_loss: 0.1335 - val_accuracy: 0.9042
Grad-CAM
さて、それぞれの可視化手法を実装し、試してみます。
まずはGrad-CAMです。
論文は以下。
Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization: https://arxiv.org/abs/1610.02391
Grad-CAMは2016年に発表されましたが、その少し前に発表されたCAM(Class Activation Mapping)の拡張として発表されました。
他のCAM手法と比較がわかりやすくなるように、数式をこちらで少し変えて表現してみました。
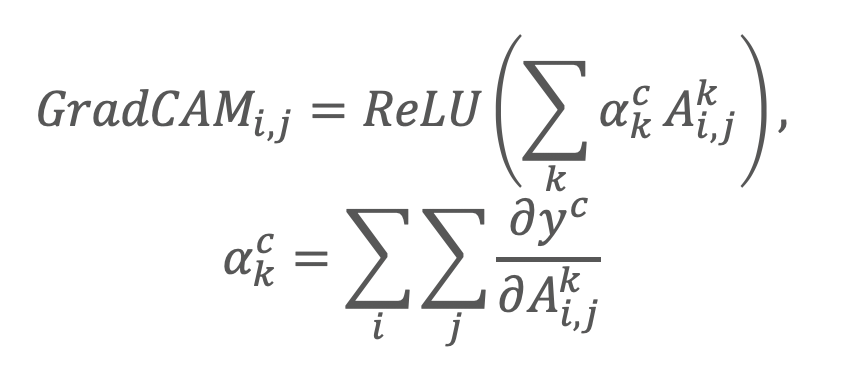
CAMは、一般的な畳み込み層に、Global Average Poolingをかけて学習させた時の特徴マップの出力は、重みがクラス分類の重要度を特徴マップ上で考えられるという考えから提案されています。
ランプ関数はクラスに対するマイナスの勾配は無視するためです。
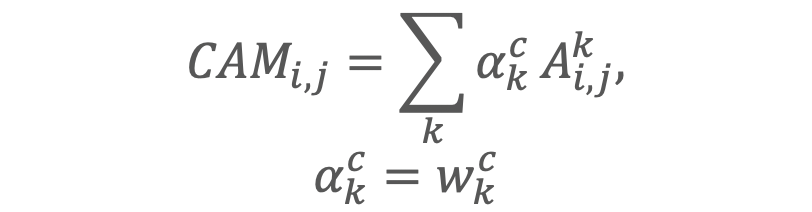
つまり、このままだとモデルとして、Global Average Poolingが必要になるのですが、それを勾配で代用できることを示し、どんなモデルアーキテクチャにも、CAMのような可視化が可能だとしたのがGrad-CAMになります。
実は上記モデル実装部分で、Global Average Pooling層を追加しましたが、多分これはなくても大丈夫だと思います。
実装は以下のようになります。
## Grad-CAM function
def grad_cam(model, x, layer_name):
"""Grad-CAM function"""
cls = np.argmax(model.predict(x))
y_c = model.output[0, cls]
conv_output = model.get_layer(layer_name).output
grads = K.gradients(y_c, conv_output)[0]
# Get outputs and grads
gradient_function = K.function([model.input], [conv_output, grads])
output, grads_val = gradient_function([x])
output, grads_val = output[0, :], grads_val[0, :, :, :]
weights = np.mean(grads_val, axis=(0, 1)) # Passing through GlobalAveragePooling
cam = np.dot(output, weights) # multiply
cam = np.maximum(cam, 0) # Passing through ReLU
cam /= np.max(cam) # scale 0 to 1.0
return cls, cam
Grad-CAM++
Grad-CAM++は、2017年に、Grad-CAMの改良版として発表されました。
Grad-CAM++: Improved Visual Explanations for Deep Convolutional Networks: https://arxiv.org/abs/1710.11063
こちらは、特徴マップにかかる重みみたいなものがあったとしたら、それはどう表現されるかを、これまでの論文で出てきた数式からガリガリと紐解いていて、以下のように表現しています。
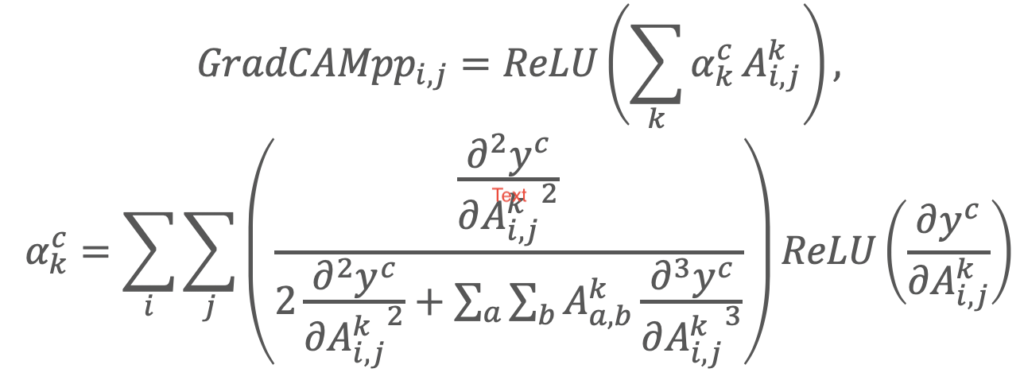
特に特徴量マップの中でクラス予測に影響を与えるが、その大きさが大きくなかったものは、これまで取れていなかったが、これにより捉えるようになった特徴などあります。
こちらを実装すると、以下のようになります。
## Grad-CAM++ function
def grad_cam_plus_plus(model, x, layer_name):
"""Grad-CAM++ function"""
cls = np.argmax(model.predict(x))
y_c = model.output[0, cls]
conv_output = model.get_layer(layer_name).output
grads = K.gradients(y_c, conv_output)[0]
first = K.exp(y_c) * grads
second = K.exp(y_c) * grads * grads
third = K.exp(y_c) * grads * grads * grads
gradient_function = K.function([model.input], [y_c, first, second, third, conv_output, grads])
y_c, conv_first_grad, conv_second_grad, conv_third_grad, conv_output, grads_val = gradient_function([x])
global_sum = np.sum(conv_output[0].reshape((-1,conv_first_grad[0].shape[2])), axis=0)
alpha_num = conv_second_grad[0]
alpha_denom = conv_second_grad[0] * 2.0 + conv_third_grad[0] * global_sum.reshape((1, 1, conv_first_grad[0].shape[2]))
alpha_denom = np.where(alpha_denom != 0.0, alpha_denom, np.ones(alpha_denom.shape))
alphas = alpha_num / alpha_denom
weights = np.maximum(conv_first_grad[0], 0.0)
alpha_normalization_constant = np.sum(np.sum(alphas, axis=0), axis=0)
alphas /= alpha_normalization_constant.reshape((1, 1, conv_first_grad[0].shape[2]))
deep_linearization_weights = np.sum((weights * alphas).reshape((-1, conv_first_grad[0].shape[2])), axis=0)
cam = np.sum(deep_linearization_weights * conv_output[0], axis=2)
cam = np.maximum(cam, 0) # Passing through ReLU
cam /= np.max(cam) # scale 0 to 1.0
return cls, cam
Score-CAM
Score-CAMは昨年2019年10月に発表された新しい手法です。
Score-CAM: Improved Visual Explanations Via Score-Weighted Class Activation Mapping: https://arxiv.org/abs/1910.01279
勾配での表現は、時々入力層のわずかな小さな変化に対しても、過剰に大きな値を返してしまう問題があります。
これは、Grad-CAMやGrad-CAM++においても指摘されていたことでした。
そこで、この論文では、特徴量ヒートマップを勾配を使わないで作成する方法を提案しています。
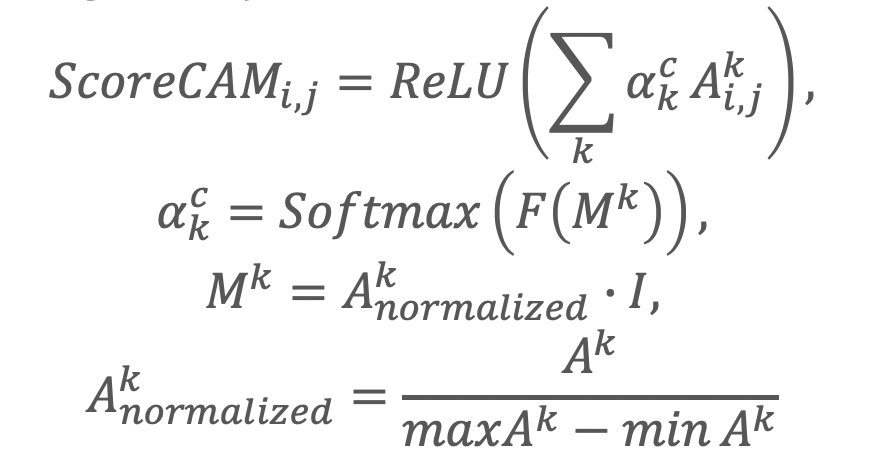
Iはインプット画像で、特徴量マップ*画像のスコアを表現するような形をしています。
これを実装すると、以下のようになります。
## Score-CAM function
def softmax(x):
"""softmax"""
return np.exp(x) / np.sum(np.exp(x), axis=1, keepdims=True)
def score_cam(model, x, layer_name, max_N=-1):
"""Score-CAM function"""
cls = np.argmax(model.predict(x))
act_map_array = Model(inputs=model.input, outputs=model.get_layer(layer_name).output).predict(x)
# extract effective maps
if max_N != -1:
act_map_std_list = [np.std(act_map_array[0, :, :, k]) for k in range(act_map_array.shape[3])]
unsorted_max_indices = np.argpartition(-np.array(act_map_std_list), max_N)[:max_N]
max_N_indices = unsorted_max_indices[np.argsort(-np.array(act_map_std_list)[unsorted_max_indices])]
act_map_array = act_map_array[:, :, :, max_N_indices]
input_shape = model.layers[0].output_shape[1:] # get input shape
# 1. upsampled to original input size
act_map_resized_list = [cv2.resize(act_map_array[0,:,:,k], input_shape[:2], interpolation=cv2.INTER_LINEAR) for k in range(act_map_array.shape[3])]
# 2. normalize the raw activation value in each activation map into [0, 1]
act_map_normalized_list = []
for act_map_resized in act_map_resized_list:
if np.max(act_map_resized) - np.min(act_map_resized) != 0:
act_map_normalized = act_map_resized / (np.max(act_map_resized) - np.min(act_map_resized))
else:
act_map_normalized = act_map_resized
act_map_normalized_list.append(act_map_normalized)
# 3. project highlighted area in the activation map to original input space by multiplying the normalized activation map
masked_input_list = []
for act_map_normalized in act_map_normalized_list:
masked_input = np.copy(x)
for k in range(3):
masked_input[0, :, :, k] *= act_map_normalized
masked_input_list.append(masked_input)
masked_input_array = np.concatenate(masked_input_list, axis=0)
# 4. feed masked inputs into CNN model and softmax
pred_from_masked_input_array = softmax(model.predict(masked_input_array))
# 5. define weight as the score of target class
weights = pred_from_masked_input_array[:, cls]
# 6. get final class discriminative localization map as linear weighted combination of all activation maps
cam = np.dot(act_map_array[0, :, :, :], weights)
cam = np.maximum(0, cam) # Passing through ReLU
cam /= np.max(cam) # scale 0 to 1.0
return cls, cam
結果の比較
各可視化の実装ができましたので、各クラスの判断根拠の可視化を比較してみます。
- 建物(buildings)
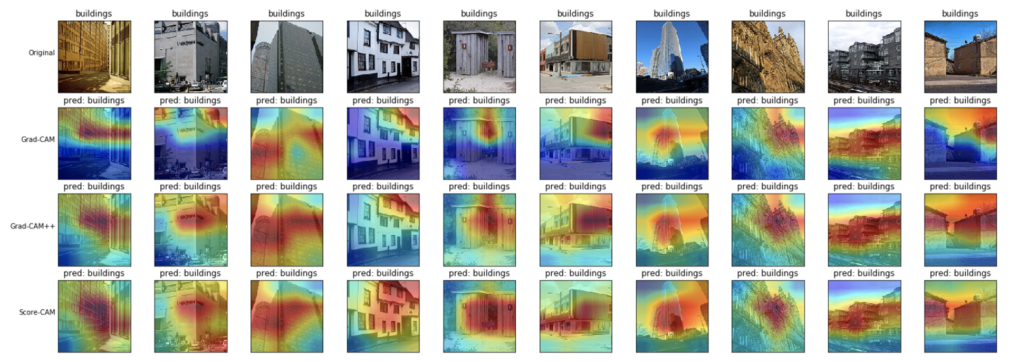
モデルは建物の全体部分に注目しているような可視化結果が得られました。
Grad-CAM++とScore-CAMの方が、Grad-CAMよりも、より建物の全体を見ているような結果となりました。
Grad-CAM++とScore-CAMはそれほど大きな違いはないように見えます。
- 森(forest)
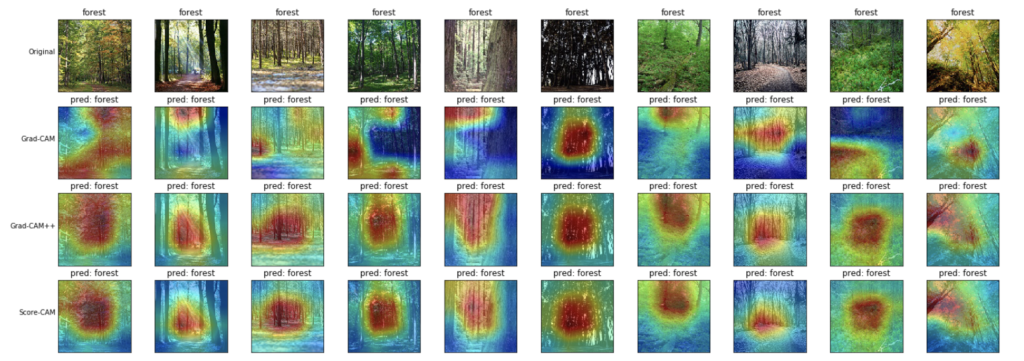
個人的には、木の幹の部分を見つけて、森と予測しているように見えます。
特に、Grad-CAM++とScore-CAMの方が、Grad-CAMよりも顕著にその特徴を捉えているように見えます。
- 雪山(glacier)
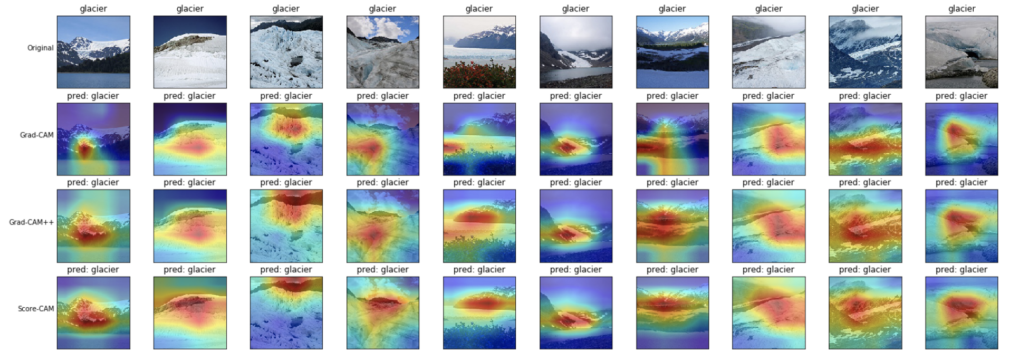
山の形を見ている?ような結果となりました。
これに関しては、いずれの可視化手法も大きな違いはなさそうに見えます。
- 山(mountain)
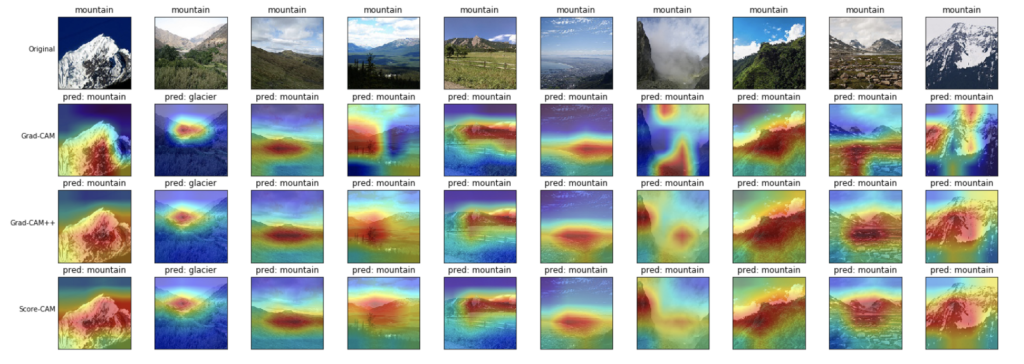
こちらも山の形を見ているような、雪山と同じような結果となりました。
山の画像にも、上記例の1列目の画像や最後の列の画像は、色的にも雪山の方が正しいような気もするし、判断に迷います。
そのくらい、差別化できるような画像要素を見つけられていないように思います。
またこちらも、いずれの可視化手法も大きな違いはなさそうです。
- 海(sea)
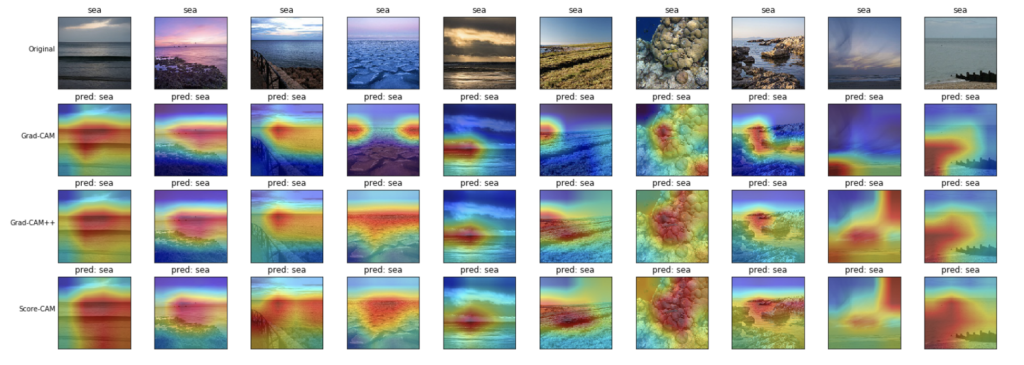
こちらは、海の表面や水平線を見ているような可視化結果となりました。
Grad-CAM++とScore-CAMの方が、Grad-CAMよりもより海全体を捉えているように見えます。
- ストリート(street)
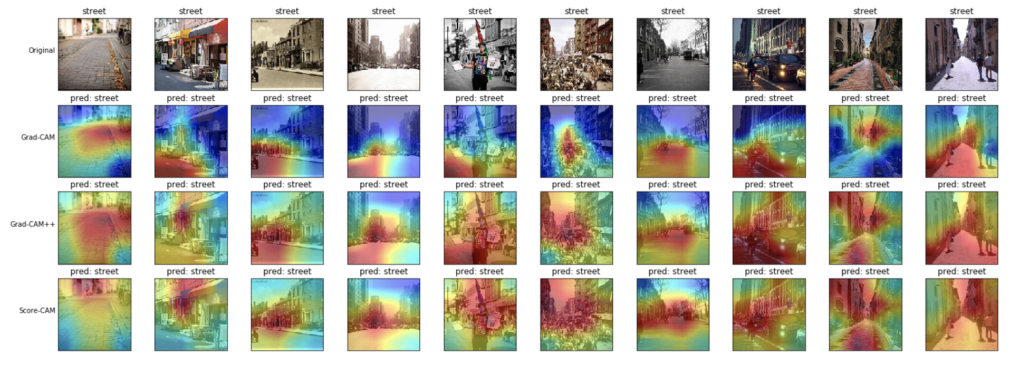
モデルは、路面およびその両側に建つ建物について見ているような結果となりました。
こちらも、Grad-CAM++とScore-CAMの方が、より全体を捉えているように見えます。
まとめ
以上、KerasでGrad-CAM、Grad-CAM++、Score-CAMの実装および結果の比較をしてみました。
Grad-CAMは、クラス予測に関連のある部分のごく一部にしか反応できていなかったように見えますが、Grad-CAM++とScore-CAMの方が、より関連のある部分全体を可視化してくれていたように見えました。
また、Grad-CAM++とScore-CAMには、可視化にはそれほど大きな違いはないようです。
また、それぞれの手法の実行時間は、新しくなるにつれて時間がかかります。(Grad-CAM < Grad-CAM++ < Score-CAM)
Grad-CAM++は、Grad-CAMよりも微分計算などが加えられて、当然実行時間は長くなります。
また、Score-CAMはマスク画像を複数枚推論する必要があるため、実行時間がかかっているように思います。
あまり時間を気にしないなら、個人的には、Grad-CAM++かScore-CAMがおすすめなのかなと思いました。
コメント
素晴らしい記事ありがとうございます。最近Grad-CAMを実装してみた初心者です。少し質問があるので、もしよろしければお教え願えるでしょうか?
Grad-CAMでRelu()で正に寄与するもののみ取り出しています。論文や各種サイトの説明でもこのようになっていますが、この意図(理由)はどう考えられるでしょうか?
負の値も考慮するほうが判断根拠の可視化としては正確な気がしますがいかがでしょうか?
またSocre-CAMのほうが広範囲にみているようですが、画像の広い部分を示されると画像のこの部分を見て判断したと言えなくなり、判断理由を他者に説明するときに不利になりそうな気がしましたが、いかがでしょうか?
お手数ですがよろしくお願い致します。
閲覧&コメントありがとうございます。
以下、個人的な認識で宜しければ回答させていただきますね。
1つ目のご質問:個人的には、勾配が負に寄与している=そのクラスではないことを表すと思うので、単純にそのクラスと判断した根拠の可視化からは除外して考えているだけなのかなあと緩く理解しておりました。なぜ正に限定するかについて記述されている論文は、読み飛ばしているかもしれませんが、確かに記憶にないですね…。
2つ目のご質問:仰る通り、使いづらい時もあるかもと思います。結局は可視化も定性的に判断せざる得ないので、クライアント等に説明する時はこちらは気休め程度であり、やはり定量的な評価を示すべきかなと思います。論文の通り、明らかに変な学習をしていないか等のデバッグ的な使い方ですとか、あとは過去の経験ですと、やっぱり画像って人間もなんとなく認識している場合も多くて、人間が見れば確かにそうなんだけど、モデルはなんでそう思ったかを、どこがどうだったからといったようにうまく言語化できなくて、ビジネス報告しづらいという時に、一部見せてあげると喜ばれることがありました。
丁寧なご回答ありがとうございます。参考にさせて頂きます。