さらに続きとしてやってみました。
前回は、花の画像データセットで、VGG16の学習済みモデルを使って特徴量を抽出してみました。
今回は表題の通り、タグ付け情報を用いてファインチューニングを行った後に、特徴量を抽出して様子を見てみようと思います。
教師データ作成
前回同様、下記のKaggleデータセットを用います。
Flower Color Images: https://www.kaggle.com/olgabelitskaya/flower-color-images
データセットの中には、約200枚の花の画像に加えて、画像ごとにそれが何の花なのかのタグ付けがされている flower-labels.csv が一緒に格納されています。
中身を見るとこんな感じです。
images = pd.read_csv('./flower_images/flower_labels.csv')
images
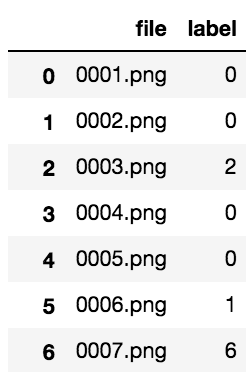
各番号は花の種類を指しています。(下記引用参照)
Label => Name
0 => phlox; 1 => rose; 2 => calendula; 3 => iris; 4 => leucanthemum maximum; 5 => bellflower; 6 => viola; 7 => rudbeckia laciniata (Goldquelle); 8 => peony; 9 => aquilegia.
これを教師データとして、学習データセットを作成します。
paths = './flower_images/' + images['file'].as_matrix()
labels = images['label'].as_matrix()
dataset = []
for path, label in tqdm(zip(paths, labels)):
img = Image.open(path)
img = L.model.vision.vgg.prepare(img)
label = np.int32(label)
dataset.append((img, label))
N = len(dataset)
今回はVGG16での学習なので、GPUを使います。
前回記事では、extractメソッドによって、画像をVGG16独自のフォーマットに変換する前処理と、順伝播を一気に行いましたが、今回はデータセットを渡すタイミングでは、画像データはGPUに送っておかなければなりません。
このあたりのGPU化などの処理はTrainerクラスなどが自動的にやってくれるのですが、そのままですと、GPU化してから順伝播でextractが呼ばれてしまい、GPUの配列データの状態で画像の前処理ができないといったエラーが発生してしまいます。
なので、今回は前処理だけ行った状態でデータセットに格納しておきたいのですが、これについては、prepareというVGG16独自の入力フォーマットに変換してくれるメソッドが用意されています。(extractでも、このprepareが中で呼ばれています)
順伝播は普通にコールすれば問題ありませんので、モデルの作成時にそのまま呼ぶようにしておきます。(後述)
分類器の実装・学習
次にモデルを作成します。
ファインチューニングでは、事前に学習されている重みを使ってある程度特徴量を抽出した上で、解きたいタスクに合わせて、ネットワークを改良します。
今回は、fc7層の後ろに、分類したいクラス分に伝播する全結合層を追加してみます。
chainermodel = './VGG_ILSVRC_16_layers.npz'
class Model(Chain):
def __init__(self, out_size, chainermodel=chainermodel):
super(Model, self).__init__(
vgg = L.VGG16Layers(chainermodel),
fc = L.Linear(None, out_size)
)
def __call__(self, x, train=True, extract_feature=False):
with chainer.using_config('train', train):
h = self.vgg(x, layers=['fc7'])['fc7']
if extract_feature:
return h
y = self.fc(h)
return y
モデルクラスができたので、インスタンスを作成してオプティマイザーをセットします。
gpu = 0
cuda.get_device(gpu).use()
model = L.Classifier(Model(out_size=len(images['label'].unique())))
alpha = 1e-4
optimizer = optimizers.Adam(alpha=alpha)
optimizer.setup(model)
model.predictor['fc'].W.update_rule.hyperparam.lr = alpha*10
model.predictor['fc'].b.update_rule.hyperparam.lr = alpha*10
model.to_gpu(gpu)
追加した最後の全結合層のパラメータは普通に学習をさせますが、引っ張ってきたVGG16のネットワーク部分のパラメータは、学習率を抑えて、あまり学習させないようにしています。
ここに関しては、色々方法があると思いますし、完全に固定(パラメータ更新をしない)のもアリだと思います。
これで準備が整いましたので、学習させてみます。
epoch_num = 15
validate_size = 30
batch_size = 30
train, test = chainer.datasets.split_dataset_random(dataset, N-validate_size)
train_iter = chainer.iterators.SerialIterator(train, batch_size)
test_iter = chainer.iterators.SerialIterator(test, batch_size, repeat=False, shuffle=False)
updater = training.StandardUpdater(train_iter, optimizer, device=gpu)
trainer = training.Trainer(updater, (epoch_num, 'epoch'), out='result')
trainer.extend(extensions.Evaluator(test_iter, model, device=gpu))
trainer.extend(extensions.LogReport())
trainer.extend(extensions.PrintReport(['epoch', 'main/loss', 'validation/main/loss', 'main/accuracy', 'validation/main/accuracy', 'elapsed_time']))
trainer.extend(extensions.PlotReport(['main/loss', 'validation/main/loss'], 'epoch', file_name='loss.png'))
trainer.extend(extensions.PlotReport(['main/accuracy', 'validation/main/accuracy'], 'epoch', file_name='accuracy.png'))
trainer.run()
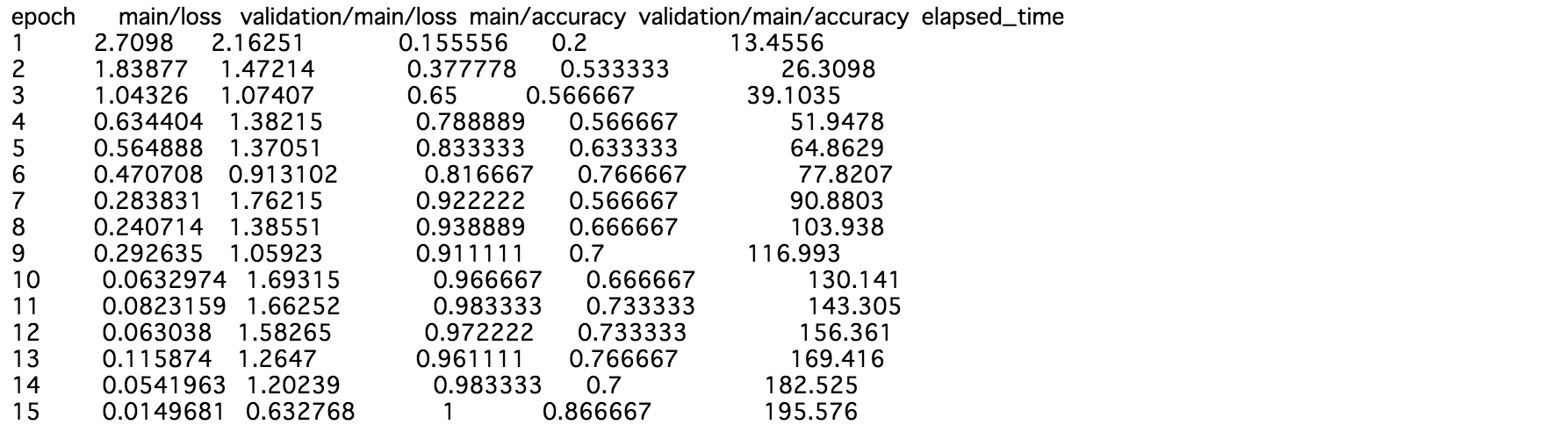
今回、花の画像が200枚程度で、かつ10クラスなので、1クラスにつき20枚程度しかないのですが、ちゃんと学習しているようです。
ファインチューニングはこういった、学習データが少ない時にも効果的です。
学習が終わったら、学習したモデルで、予測、特徴量抽出を実行してみます。(データが少ないため、学習に利用したデータも含めてしまっていますが...)
ys_pre, ys, features = [], [], []
for path, label in tqdm(zip(paths, labels)):
img = Image.open(path)
img = L.model.vision.vgg.prepare(img)
img = img[np.newaxis, :]
img = cuda.to_gpu(img)
y_pre = model.predictor(img)
y_pre = y_pre.data.reshape(-1)
y_pre = np.argmax(y_pre)
feature = model.predictor(img, extract_feature=True)
feature = feature.data.reshape(-1)
feature = cuda.to_cpu(feature)
ys_pre.append(y_pre)
ys.append(label)
features.append(feature)
ys = np.array(ys, dtype=np.int32)
ys_pre = np.array(ys_pre, dtype=np.int32)
features = np.array(features, dtype=np.float32)
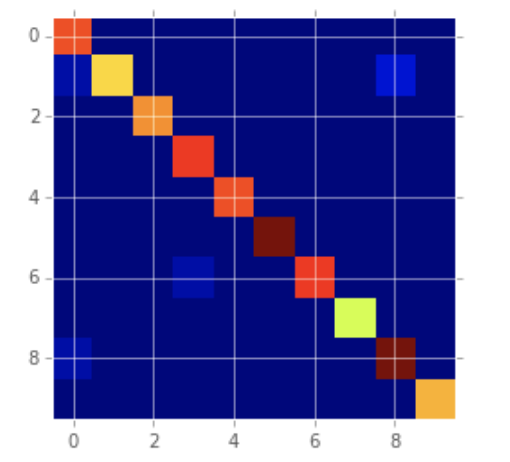
予測ラベルと正解ラベルの混合行列を可視化してみると、ちゃんと予測できていることが確認できます。
from sklearn.metrics import confusion_matrix
plt.imshow(confusion_matrix(ys, ys_pre), interpolation='nearest')
plt.show()
t-SNEによる特徴量の可視化
次に得られた特徴量をt-SNEで圧縮して2次元プロットしてみます。
前回よりも良い感じに、似た花が近くにプロットされるでしょうか。
from sklearn.manifold import TSNE
tsne_model = TSNE(n_components=2).fit_transform(features)
canvas_size = (1500, 1500)
img_size = (50, 50)
canvas = Image.new('RGB', canvas_size)
val_max = np.array(tsne_model).max()
val_min = np.array(tsne_model).min()
for i, path in enumerate(paths):
pos_x = int(tsne_model[i][0]*(canvas_size[0]/img_size[0])/(val_max-val_min))*img_size[0]
pos_y = int(tsne_model[i][1]*(canvas_size[1]/img_size[1])/(val_max-val_min))*img_size[1]
pos = (int(pos_x+canvas_size[0]/2), int(pos_y+canvas_size[1]/2))
target_img = Image.open(path)
target_img = target_img.resize(img_size)
canvas.paste(target_img, pos)
target_img.close()
plt.figure(figsize=(15,15))
plt.imshow(np.array(canvas))
plt.axis('off')
plt.show()

あれ?
思ったより綺麗ではない。
と、一瞬思いましたが、よく見てみると、色が違うけども同じ花と思われる画像が近くにプロットされているような箇所が見受けられます。
そこで、前回同様に特徴量のコサイン類似度を計算して、類似度が高いものを、ラベルと一緒に並べて表示させてみます。
def cos_sim_matrix(matrix):
d = matrix @ matrix.T
norm = (matrix * matrix).sum(axis=1, keepdims=True) ** .5
return d / norm / norm.T
cos_sims = cos_sim_matrix(features)
samples = np.random.randint(0, len(paths), 10)
for i in samples:
sim_idxs = np.argsort(cos_sims[i])[::-1]
sim_idxs = np.delete(sim_idxs, np.where(sim_idxs==i))
sim_num = 3
sim_idxs = sim_idxs[:sim_num]
fig, axs = plt.subplots(ncols=sim_num+1, figsize=(15, sim_num))
img = Image.open(paths[i])
axs[0].imshow(img)
axs[0].set_title('target\n'+str(labels[i]))
axs[0].axis('off')
for j in range(sim_num):
img = Image.open(paths[sim_idxs[j]])
axs[j+1].imshow(img)
axs[j+1].set_title(str(cos_sims[i, sim_idxs[j]])+'\n'+str(labels[sim_idxs[j]]))
axs[j+1].axis('off')
plt.show()



なるほど...。
ラベルの情報が加わったことにより、画像(画素値)による特徴量だけでなく、付与されているラベルの値が近いものがプロットされるようになったみたいです。
言われてみれば当たり前ですね。
このように、付与されたタグの情報が与える影響が確認できたため、このことから、何を持って「似ている」として、どういった情報を与えるのかを考えなければならないことが分かりました。
ともあれ、学習に関してはうまくいっていそうで、安心しました。
ということで、今回はChainerでファインチューニングを実装してみました。
今回のソースコードは下記にあげております。
GitHub: https://github.com/Gin04gh/kaggle/blob/master/datasets/Flower_Color_Images/FinetuningVGG16.ipynb
移設&少し更新しました。
近い画像のものが、という意味では、確かに同じ種類の花が出るようにはなりましたが、その他の画像系タスクでも、こういったファインチューニングをどんどん試してみたいですね。
今回はVGG16でしたけども、他の学習済みモデルでも、どういった実装や挙動になるか、動かしてみたいです。
追記(2018-04-04)
他の学習済みモデルの使い方もまとめてみました。
コメント