政府統計データのいろんな地域別のデータを眺めながら、先日のマップ可視化に乗せるだけでも面白いなぁとか考えていました。
今回は、タイトルの通りの集計データから、業種別で趣味の傾向があるのかどうか、見えたりするのかとか思ったので、調べてみました。
対応分析
今回は対応分析を使って、結果を可視化してみることにします。
対応分析は、コレスポンデンス分析や数量化3類とも呼ばれる手法で、考え方は、分割表(行列)において、行と列の相関が最大になるように、行と列の双方を並び替えることです。
相関が最大になるように並べ替えるということは、クロス表の各セルにあるデータを見ながら、近い項目が隣り合うように並べ替えるということになります。
実装
性別、職業別、趣味別の行動者数データ :
上記のダウンロードして、簡単にデータ部分だけCSVで切り取りまして、下記の構造のデータを用意しました。
data.csv の構造
| 趣味1 | 趣味2 | ... | 趣味m | ||
| 総数 | 職業1 | データ | |||
| 職業2 | |||||
| ... | |||||
| 職業n | |||||
| 男 | 職業1 | ||||
| 職業2 | |||||
| ... | |||||
| 職業n | |||||
| 女 | 職業1 | ||||
| 職業2 | |||||
| ... | |||||
| 職業n | |||||
Rプログラムを以下のようにしておきます。コマンドラインからファイル名を指定して実行できるようにしたいので、commandArgsで引数を取れるようにしました。
corresp.R
library(MASS)
argv <- commandArgs(T)
input_file <- argv[1]
nf <- as.numeric(argv[2])
data <- read.table(input_file, sep=",", header=T, row.names=1)
data.corresp <- corresp(data, nf=nf)
f <- paste(input_file, "png", sep=".")
png(f)
biplot(data.corresp)
dev.off()
Rubyで実行します。(Rで多重クロス集計表をそのまま多重対応分析する方法もあるらしいのですが、よく分かりませんでした!)
exec.rb
# -*- coding: utf-8 -*-
require "fileutils"
col_names = Hash.new()
row_names = Hash.new()
all_data = Array.new()
man_data = Array.new()
woman_data = Array.new()
input_file = "data.csv"
col_names_file = "col_names"
row_names_file = "row_names"
all_file = "all.csv"
man_file = "man.csv"
woman_file = "woman.csv"
FileUtils.safe_unlink([col_names_file, row_names_file, all_file, man_file, woman_file, all_file + ".png", man_file + ".png", woman_file + ".png"])
sex = ""
File.open(input_file, "r:Shift_JIS:UTF-8") do |f|
cnt = 0
while line = f.gets
cnt = cnt + 1
arr = line.gsub(/(\r|\n)/, "").split(",")
sex_tmp = arr.shift
if cnt == 1
arr.each_with_index do |a, i|
col_names[a.gsub(/(.*?)|【千人】/, "")] = i == 0 ? "" : "C" + i.to_s
end
next
end
sex = sex_tmp if sex_tmp != "" && sex_tmp != sex
case sex
when "総数" then all_data.push(arr)
when "男" then man_data.push(arr)
when "女" then woman_data.push(arr)
end
end
end
all_data.each_with_index do |row, i|
row_names[row[0].gsub(/うち|従事者/, "")] = "R" + (i + 1).to_s
end
nf = col_names.size - 1 < row_names.size ? col_names.size - 1 : row_names.size
[all_data, man_data, woman_data].each do |data|
data.each do |row|
row.collect! do |d|
d = d.gsub(/うち|従事者/, "").gsub("-", "0")
d = d.match(/^[0-9]+$/) ? d + "000" : row_names[d]
end
end
data.unshift(col_names.values)
end
[[all_data, man_data, woman_data], [all_file, man_file, woman_file]].transpose.each do |data, file|
data.each do |row|
File.open(file, "a") do |f|
f.puts(row.join(","))
end
end
end
col_names.delete("")
[[col_names, row_names], [col_names_file, row_names_file]].transpose.each do |names, file|
names.each do |key, value|
File.open(file, "a") do |f|
f.puts(value + ":" + key)
end
end
end
[all_file, man_file, woman_file].each do |file|
cmd = "Rscript corresp.R " + file + " " + nf.to_s
res = system(cmd)
end
exit
ruby exec.rb
結果、行名と列名、各プロット図が以下の通りになりました。
col_names
C1:スポーツ観覧 C2:美術鑑賞 C3:演芸・演劇・舞踊鑑賞 C4:映画鑑賞 C5:音楽会などによるクラシック音楽鑑賞 C6:音楽会などによるポピュラー音楽・歌謡曲鑑賞 C7:CD・テープ・レコードなどによる音楽鑑賞 C8:DVD・ビデオなどによる映画鑑賞 C9:楽器の演奏 C10:邦楽 C11:コーラス・声楽 C12:邦舞・おどり C13:洋舞・社交ダンス C14:書道 C15:華道 C16:茶道 C17:和裁・洋裁 C18:編み物・手芸 C19:趣味としての料理・菓子作り C20:園芸・庭いじり・ガーデニング C21:日曜大工 C22:絵画・彫刻の制作 C23:陶芸・工芸 C24:写真の撮影・プリント C25:詩・和歌・俳句・小説などの創作 C26:趣味としての読書 C27:囲碁 C28:将棋 C29:パチンコ C30:カラオケ C31:テレビゲーム・パソコンゲーム C32:遊園地,動植物園,水族館などの見物 C33:キャンプ C34:その他
row_names
R1:農林漁業 R2:管理的職業 R3:専門的・技術的職業 R4:事務 R5:販売 R6:サービス職業 R7:保安職業 R8:生産工程 R9:輸送・機械運転 R10:建設・採掘 R11:運搬・清掃・包装等
all.csv.png
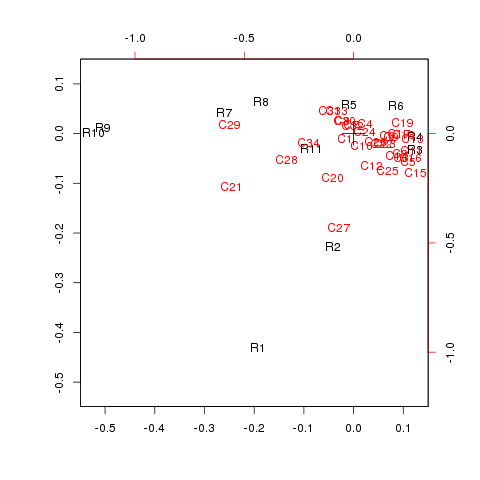
man.csv.png
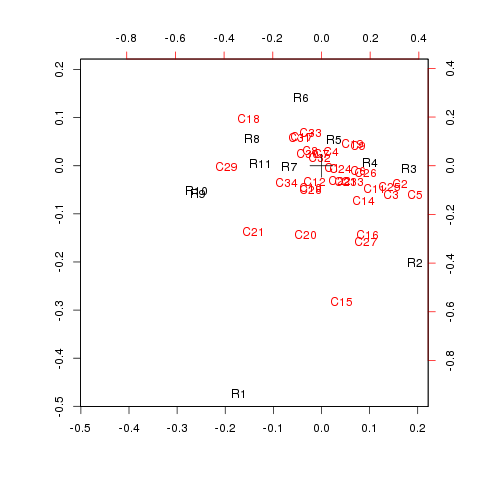
woman.csv.png
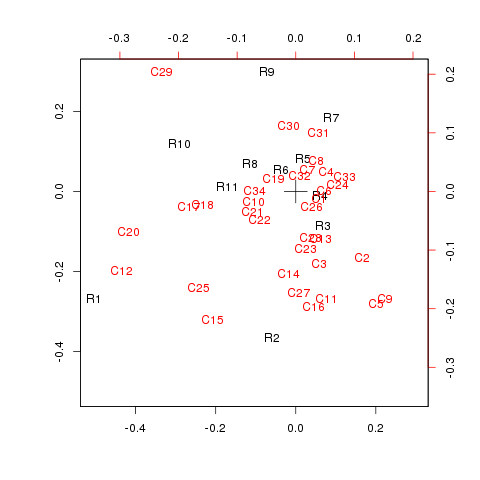
ちょっと項目多くて、わけわかんないことに…。
R7とC29が近いのはなんでなん?笑
R1に対して、C12やC20が比較的近い目のはなんとなく頷ける気がします。
見ていると、全体としてなんとなく職業に対する年齢層の割合との関連が薄っすらと見えるようにも感じました。
コメント