表題の通り、潜在ディリクレ配分法(LDA; Latent Dirichlet Allocation)によるトピックモデルを学習させて、WordCloud・pyLDAvisで可視化までやってみます。
データセットの用意
今回は日本語でやってみたかったので、以下のlivedoorニュースコーパスを利用させていただきました。
- https://www.rondhuit.com/download.html
日本語のコーパスとしては定番ですね。
ダウンロードしてきた圧縮ファイルを解凍して、各ドキュメントのパスを読み込んでおきます。
import glob
import numpy as np
import pandas as pd
from tqdm import tqdm
np.random.seed(0)
text_paths = glob.glob('livedoor-news-corpus/text/**/*.txt')
len(text_paths) # 7376
1つドキュメントを開いてみると、以下のように、
- ニュース記事のURL
- 日時
- タイトル
- 本文
といった順番でテキストファイルで格納されています。
print(open(text_paths[0], 'r').read())

LDAの学習
さっそくデータを加工して、LDAしていきます。
データをprocessingする関数を以下のように用意。
import MeCab
def analyzer(text, mecab, stopwords=[], target_part_of_speech=['proper_noun', 'noun', 'verb', 'adjective']):
node = mecab.parseToNode(text)
words = []
while node:
features = node.feature.split(',')
surface = features[6]
if (surface == '*') or (len(surface) < 2) or (surface in stopwords):
node = node.next
continue
noun_flag = (features[0] == '名詞')
proper_noun_flag = (features[0] == '名詞') & (features[1] == '固有名詞')
verb_flag = (features[0] == '動詞') & (features[1] == '自立')
adjective_flag = (features[0] == '形容詞') & (features[1] == '自立')
if ('proper_noun' in target_part_of_speech) & proper_noun_flag:
words.append(surface)
elif ('noun' in target_part_of_speech) & noun_flag:
words.append(surface)
elif ('verb' in target_part_of_speech) & verb_flag:
words.append(surface)
elif ('adjective' in target_part_of_speech) & adjective_flag:
words.append(surface)
node = node.next
return words
日本語なので形態素解析が必要です。ここはMeCabで。
名詞や固有名詞、動詞、形容詞などを指定して取ってこれるようにしてみました。
ストップワードは以下の日本語用のストップワードを公開しているページから拝借します。
import urllib
req = urllib.request.Request('http://svn.sourceforge.jp/svnroot/slothlib/CSharp/Version1/SlothLib/NLP/Filter/StopWord/word/Japanese.txt')
with urllib.request.urlopen(req) as res:
stopwords = res.read().decode('utf-8').split('\r\n')
while '' in stopwords:
stopwords.remove('')
print(stopwords)

これらを使って、先ほどの1つ目のドキュメントのタイトルと本文を構成する単語(名詞・固有名詞)を取得してみると、
text = open(text_paths[0], 'r').read()
text = text.split('\n')
title = text[2]
text = ' '.join(text[3:])
mecab = MeCab.Tagger('-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd')
words = analyzer(text, mecab, stopwords=stopwords, target_part_of_speech=['noun', 'proper_noun'])
print(title)
print(words)

といった感じ。
動作は問題なさそうです。
さて、LDAはpythonでおなじみのライブラリgensimを使います。
gensim: https://radimrehurek.com/gensim/
gensimと先ほど作成したアナライザーを使って、単語IDの辞書とコーパスを作成します。
import gensim
mecab = MeCab.Tagger('-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd')
titles = []
texts = []
for text_path in text_paths:
text = open(text_path, 'r').read()
text = text.split('\n')
title = text[2]
text = ' '.join(text[3:])
words = analyzer(text, mecab, stopwords=stopwords, target_part_of_speech=['noun', 'proper_noun'])
texts.append(words)
dictionary = gensim.corpora.Dictionary(texts)
dictionary.filter_extremes(no_below=3, no_above=0.8)
corpus = [dictionary.doc2bow(t) for t in texts]
print('vocab size: ', len(dictionary)) # vocab size: 28824
これでモデル学習の準備は完了。
早速分析しようと思いますが、LDAは分析者が指定するパラメータがたくさんあります。
しかも教師なし学習なので、最適なパラメータを決めるようなグリッドサーチなどは出来ません。
ただし、対数尤度やCoherenceなど、トピックモデリングがうまくいっていることをうまく説明しようとした指標などもいくつか考えられており、これが最適になるようなパラメータを指定するといった方法などはいくつかあります。
しかし、どれも人間の直感としてどうなのかといった疑念もあるようで、やっぱりいまいちこれという方法はないみたいです。
試しに、特にモデル結果の解釈性に大きく影響を与えるトピック数について、色々と値を変えてLDAを学習させて、PerplexityおよびCoherenceを算出させてプロットさせてみました。
Perlexityについて参考になるURLは以下など。
Coherenceについて参考になるURLは以下など
import matplotlib
import matplotlib.pylab as plt
font = {'family': 'TakaoGothic'}
matplotlib.rc('font', **font)
start = 2
limit = 50
step = 2
coherence_vals = []
perplexity_vals = []
for n_topic in tqdm(range(start, limit, step)):
lda_model = gensim.models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=n_topic, random_state=0)
perplexity_vals.append(np.exp2(-lda_model.log_perplexity(corpus)))
coherence_model_lda = gensim.models.CoherenceModel(model=lda_model, texts=texts, dictionary=dictionary, coherence='c_v')
coherence_vals.append(coherence_model_lda.get_coherence())
x = range(start, limit, step)
fig, ax1 = plt.subplots(figsize=(12,5))
c1 = 'darkturquoise'
ax1.plot(x, coherence_vals, 'o-', color=c1)
ax1.set_xlabel('Num Topics')
ax1.set_ylabel('Coherence', color=c1); ax1.tick_params('y', colors=c1)
c2 = 'slategray'
ax2 = ax1.twinx()
ax2.plot(x, perplexity_vals, 'o-', color=c2)
ax2.set_ylabel('Perplexity', color=c2); ax2.tick_params('y', colors=c2)
ax1.set_xticks(x)
fig.tight_layout()
plt.show()
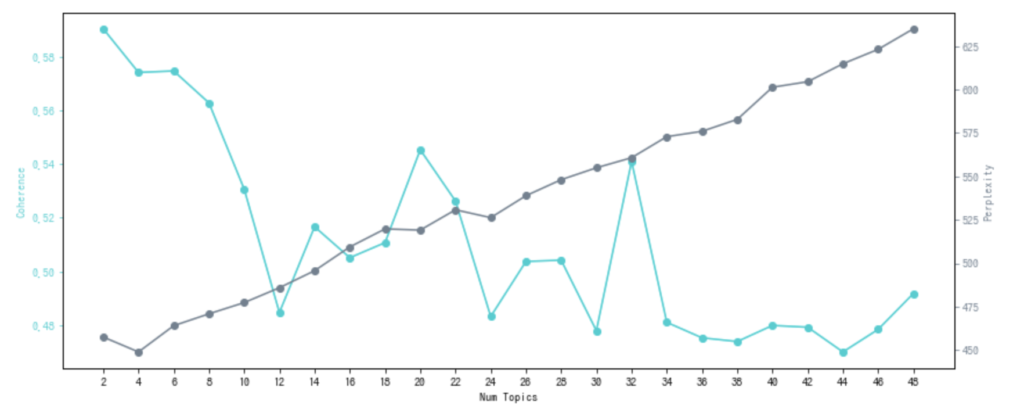
Perplexityは低ければ低いほど、Coherenceは高ければ高いほど良いとされていますが、これを見る限り、トピック数2が良いという結果になってしまいました。
そもそも、Perplexityはトピック数を増やすたびに上昇しているようで、これをもって解釈性の良し悪しを決めるのは、何か無理があるような気がします。
Coherenceにしても、一番高いところの値、もしくはCoherenceが上がり続けるような曲線を描いた場合には、対数関数っぽく平坦化してくる部分の手前で最も高いCoherenceの値が算出されたパラメータ値を利用するらしいですが、たいていの実データで実行した場合は、今回のように減少関数っぽくなってしまいます。
これだとあまり決められないので、ひとまず今回は、結果の解釈性なども見て、トピック数8にしました。
lda_model = gensim.models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=8, random_state=0)
Perplexityにしてみれば、およそ475ぐらいですので、単語をランダムに選択した場合の語彙数28,824通りに対して、475通りぐらいにまで絞れていると考えていると、それはそれで結構良い性能のようにも聞こえます。
トピックモデリングの評価指標に関してはずっと課題のようで、Perplexity、Coherenceだけでなく、他にも様々考えられているようです。
まあ、トピックモデリングに限らず、教師なし学習がうまくいっていそうかといった考え方や評価などはずっと課題のようですね。
Word Cloud
それでは、学習させたLDAの結果を可視化させてみます。
Word Cloudのビジュアライズは、なんかデータサイエンスやってる感を出すのに向いています←
以下のようにフォントを指定したり、色などの指定、またマスク画像の指定などを行うことができます。
from wordcloud import WordCloud
from PIL import Image
fig, axs = plt.subplots(ncols=4, nrows=int(lda_model.num_topics/4), figsize=(15,7))
axs = axs.flatten()
def color_func(word, font_size, position, orientation, random_state, font_path):
return 'darkturquoise'
mask = np.array(Image.open('ball.png'))
for i, t in enumerate(range(lda_model.num_topics)):
x = dict(lda_model.show_topic(t, 30))
im = WordCloud(
font_path='logotypejp_mp_b_1.1.ttf',
background_color='white',
color_func=color_func,
mask=mask,
random_state=0
).generate_from_frequencies(x)
axs[i].imshow(im)
axs[i].axis('off')
axs[i].set_title('Topic '+str(t))
plt.tight_layout()
plt.show()

こうして見ると、
- トピック0: スポーツ関連のニュース
- トピック4: 携帯端末関連のニュース
- トピック7: 「独女通信」関連のニュース
その他は、IT系って感じがしますかね?
pyLDAvis
pyLDAvisを使うと、LDAの結果をインタラクティブに可視化することができます。
pyLDAvis: https://github.com/bmabey/pyLDAvis
import pyLDAvis
import pyLDAvis.gensim
pyLDAvis.enable_notebook()
vis = pyLDAvis.gensim.prepare(lda_model, corpus, dictionary, sort_topics=False)
vis
以下のように、HTMLにして保存することも可能です。
以下に吐き出したHTMLのリンクを貼り付けましたので、リンク先でぐりぐり触って遊んでみて下さい。
pyLDAvis.save_html(vis, 'pyldavis_output.html')
※画像をクリックするとページが開きます。
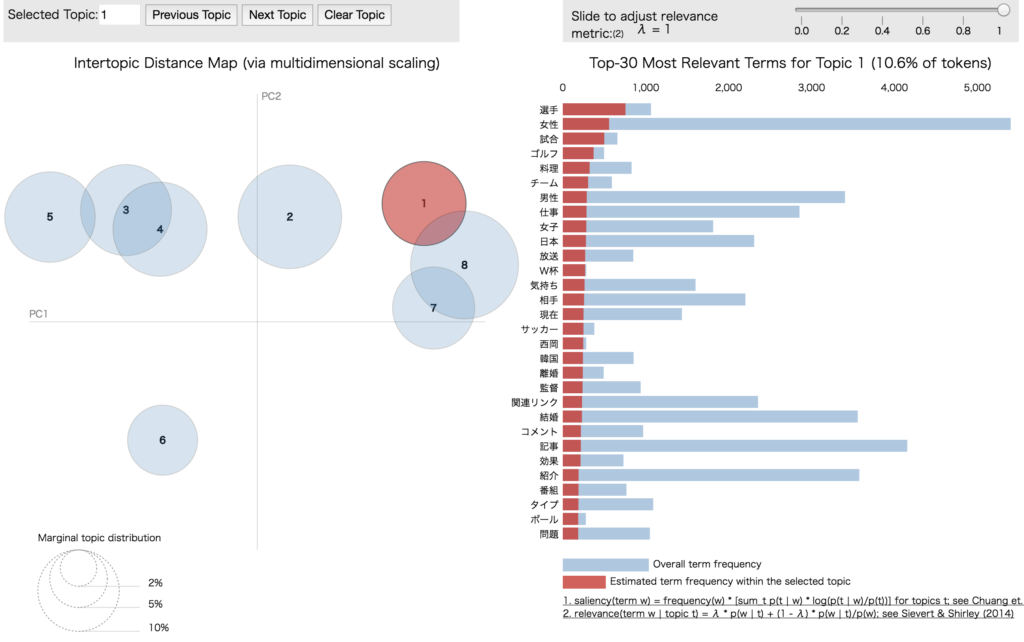
トピックに含まれるドキュメント数で円の大きさが変わり、またトピックごとの単語分布の主成分分析結果で、トピック間の距離を視覚的に可視化してくれています。
こうして見たときにあまり交わらないようにトピック数を決めたり、その他パラメータを決めるのも良いかもしれません。
右側の棒グラフは、単語の発生頻度と選択トピック内での発生頻度、パラメータλを変えると、この2つの比率を変えて順位を変えられます。
また、単語にオンマウスすると、その単語のトピックごとの発生頻度が左側で円の大きさとなって可視化されます。
まとめ
gensimでLDAを行なって、可視化の方法を2つ試しました。
pyLDAvisは、パラメータλによって解釈性が大きく変化することもありますし、ストップワードや単語発生頻度の上限下限を決める手掛かりをインタラクティブに探すのも向いていそうです。
しかし、LDAなどのトピックモデリングは以前にも勉強がてら少しだけ動かして「これは難しそうだな」という感覚はありましたが、やっぱり難しいですね。
だけど、最近ではNLP分野はEmbeddingによりだいぶ進歩していますので、こういったトピックモデリングの分野もEmbeddingがやはり効果を発揮しそう。
そういう目線から見ると、Gaussian LDAなどはどんな感じなのか個人的に気になるので、暇があればこういうのも試していきたいですね。
コメント