Google子会社DeepMind社により開発された、人工知能を搭載したコンピューター囲碁プログラム「AlphaGo(アルファ碁)」の活躍により、深層学習や強化学習の注目度がさらに上がった気がします。
このDeepMind社が考案した深層強化学習(Deep Q-Network)を実装してみようと思い、であれば、まずは強化学習を勉強したいということで、ひとまず今回は強化学習をPythonで実装してみました。
強化学習
強化学習(Reinforcement Learning)は、「ある環境内におけるエージェントが、現在の状態を観測し、取るべき行動を決定する問題を扱う機械学習の一種」です。(Wikipediaより)
機械学習の書籍では、機械学習の種類として「教師なし学習」と「教師あり学習」に加えて、3つ目に「強化学習」がよく挙げられていることが多い気がします。
ある環境内に置かれたエージェントは、環境の状態ごとに施策(行動を決定するルール)に基づいて行動を決定して、次の状態に遷移して報酬を受け取ります。
これを繰り返して、より多くの累積報酬を得られるような施策を学習する方法が強化学習です。
今回は、有限マルコフ決定過程な環境において、上記のような、より多い累積報酬を得る施策として、行動価値関数Qを用いた学習方法を実装します。
Q学習
エージェントが各状態において選択できる行動の中で、最も行動価値関数の値が高い行動を選択するように学習する方法をQ学習と言います。
学習は、エージェントが行動を選択し、遷移した状態とその時に得られた報酬を用いて、その時の行動価値関数Qの値を更新することを繰り返すことで行います。
例えば、 エージェントの学習率が  、割引率が
、割引率が  であるとして、状態
であるとして、状態  のエージェントが行動
のエージェントが行動  を選択し、報酬
を選択し、報酬  を得て、状態が
を得て、状態が  に遷移したとすると、このときの行動価値関数Qの値
に遷移したとすると、このときの行動価値関数Qの値  を次の式で更新します。
を次の式で更新します。
![\[\displaystyle Q_{s_t, a_t} \leftarrow Q_{s_t, a_t}+\alpha{r_{t+1}+\gamma\max_{a_{t+1}}Q(s_{t+1}, a_{t+1})-Q(s_t, a_t)}\]](https://ie110704.net/wp-content/ql-cache/quicklatex.com-e376a68f1275ca1424c2b78fcb86205c_l3.png "Rendered by QuickLaTeX.com")
学習率は、エージェントが行動の価値をどのくらいの割合で学習するかを表すパラメータであり、割引率は、将来もらえる報酬を現在の価値としてどのくらいの割合とするかを表すパラメータになります。
行動の選択は、今回は、基本的には行動価値関数の価値が高い行動を選びつつ、一定確率εでランダムに行動を選ぶように行動を選択させる、ε-greedy法という手法を用います。
他にもボルツマン分布に従う確率で行動を選択する方法などもあるようです。
ちなみに、冒頭で記した深層強化学習(Deep Q-Network)は、最適な行動価値関数Qを直接得ることが困難なくらい状態や行動が複雑な場合に、その関数の近似を得るために深層学習を用いるといった手法になります。
これについてはまた後日まとめます。
追記(2017-02-20)
実装しました。
Open AI Gym
上記のような強化学習のプログラムを実行するには、強化学習で解く問題(環境)をプログラム上で用意しなければなりませんが、そういった強化学習用の環境を提供するプラットフォームとして「Open AI Gym」というものがあります。
Open AI Gym : https://gym.openai.com/
Open AI Gymが提供してくれるのは、環境(行動空間、状態空間、報酬)のみです。
これに対して、強化学習アルゴリズムを自分で実装して、環境に試してみることで、強化学習プログラムの評価を行うことができます。
FrozenLakeをQ学習で解いてみる
実際に、提供されている環境を選んで、Q学習で解いてみました。
今回はToy textの「FrozenLake-v0」という環境にしました。
簡単に環境の説明をすると、下記のような、4×4のマスを想定し、Sがエージェントの現在地、Fが道、Hが穴(落ちるとゲームオーバーでマイナス報酬を得る)、Gがゴール(ここに来て初めてプラス報酬を得る)で、Gに向かうようエージェントを行動(移動)させるといった、経路探索の問題になります。
| S | F | F | F |
| F | H | F | H |
| F | F | F | H |
| H | F | F | G |
Pythonで強化学習で解いたプログラムが下記になります。
本当はクラス化するべきだと思いますが、ひとまずは一直線に学習するだけの流れでコーディングしました。
import gym
import numpy as np
%matplotlib inline
import matplotlib.pylab as plt
env = gym.make("FrozenLake-v0")
n_obs = env.observation_space.n
n_act = env.action_space.n
q = np.zeros([n_obs, n_act])
epoch_cnt = 20000
max_steps = 200
epsilon = 0.001
gamma = 0.9
alpha = 0.9
rewards = np.zeros(epoch_cnt)
for epoch in range(epoch_cnt):
pobs = env.reset()
done = False
for step in range(max_steps):
pact = np.argmax(q[pobs, :])
pact = np.random.choice(np.where(q[pobs, :] == q[pobs, pact])[0])
if np.random.rand() <= epsilon:
pact = env.action_space.sample()
obs, reward, done, _ = env.step(pact) # return observation, reward, done, info
if not done:
q[pobs, pact] += alpha * (reward - q[pobs, pact] + gamma * np.max(q[obs, :]))
else:
q[pobs, pact] += alpha * (reward - q[pobs, pact])
pobs = obs
rewards[epoch] = reward
if done:
break
rates = np.average(rewards.reshape([epoch_cnt//1000, 1000]), axis = 1)
plt.plot(rates)
plt.savefig("result.png")
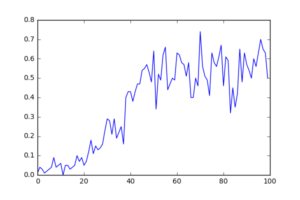
最初はすぐに穴に落ちたり、なかなかゴールにたどり着けていませんが、エピソード数を重ねるごとに、だんだんとゴールするようになって報酬を得るように学習しています。
さて、今回はQ学習でFrozenLakeを解きましたが、他にもOpen AI Gymの中ですと、Atariのゲームなどは解いてみたいですね。
Deep Q-NetworkでQ関数に畳み込みニューラルネットワークを使うことになるのですが、処理性能もかなりの物が求められると思います。
GPUも必要になってくると思いますので、とりあえず一番の課題はお金ですね←
追記(2018-09-10)
上記とコードが若干異なりますが、上記と同じ問題をGitHubにあげておきました。
- https://github.com/Gin04gh/datascience/blob/master/open_ai/q-learning_frozenlake.ipynb
コメント