前回、強化学習で解いた問題を、今回は深層強化学習(Deep Q-Network、以降DQN)で解いてみます。
DQNを使うほどの問題ではないのですが、実装の勉強のため、簡単な問題で解いてみました。
Deep Q-Network
前回も少し触れましたが、DQNは、Q学習の行動価値関数  の近似関数を深層学習で求める手法です。
の近似関数を深層学習で求める手法です。
状態  から行動
から行動  を選択して、報酬
を選択して、報酬  を受け取って状態
を受け取って状態  に遷移したとします。
に遷移したとします。
この時にニューラルネットワーク  に状態 を入力した時に出力される行動ベクトル
に状態 を入力した時に出力される行動ベクトル  の に当たる確率を下記で更新します。
の に当たる確率を下記で更新します。
(DeepMind社の論文を読んでいて、ここが一番理解に苦労しました...)
![\[{\displaystyle}y_t = Q(s_t)\]](https://ie110704.net/wp-content/ql-cache/quicklatex.com-b74c2732bd170ed5688da25d8d8c7b26_l3.png "Rendered by QuickLaTeX.com")
![\[{\displaystyle}y_t[a_t] \leftarrow r_t+{\max}Q(s_t)\]](https://ie110704.net/wp-content/ql-cache/quicklatex.com-3579c1035699abfdf0eaf2b5785b47b5_l3.png "Rendered by QuickLaTeX.com")
また、学習に使う「状態・行動・報酬」のセットは、互いに相関のないものを使った方が収束が早くなるそうです。
Q学習では、行動をさせるたびに「状態・行動・報酬」を使ってQ関数を更新していましたが、DQNでは「状態・行動・報酬」を一旦保存しておいて、そこからランダムにミニバッチ分取り出し、確率勾配降下法でニューラルネットワークの重みを更新していくようです。
FrozenLakeをDeep Q-Networkで解いてみる
Open AI GymやFrozen Lakeの環境の説明については、前回記事と同様なので省略します。
ニューラルネットワークの実装には、下記らの記事と同様、フレームワークのChainerを使いました。
実装が下記になります。
GitHub: https://github.com/Gin04gh/open_ai_gym/blob/master/DQN_NN_FrozenLake.ipynb
上記、移設しました。
GitHub: https://github.com/Gin04gh/datascience/blob/master/open_ai/dqn_nn_frozenlake.ipynb
import copy, sys
import numpy as np
%matplotlib inline
import matplotlib.pylab as plt
import gym
import chainer
import chainer.links as L
import chainer.functions as F
from chainer import Chain, optimizers, Variable, serializers
class Neuralnet(Chain):
def __init__(self, n_in, n_out):
super(Neuralnet, self).__init__(
l1 = L.Linear(n_in, 100),
l2 = L.Linear(100, 100),
l3 = L.Linear(100, 100),
q_value = L.Linear(100, n_out, initialW=np.zeros((n_out, 100), dtype=np.float32))
)
def Q_func(self, x):
h = F.leaky_relu(self.l1(x))
h = F.leaky_relu(self.l2(h))
h = F.leaky_relu(self.l3(h))
h = self.q_value(h)
return h
def main():
sys.setrecursionlimit(10000)
env = gym.make("FrozenLake-v0")
n_obs = env.observation_space.n
n_act = env.action_space.n
q = Neuralnet(n_obs, n_act)
target_q = copy.deepcopy(q)
optimizer = optimizers.Adam()
optimizer.setup(q)
loss = 0
total_step = 0
gamma = 0.99
memory = []
memory_size = 1000
batch_size = 100
epsilon = 1
epsilon_decrease = 0.005
epsilon_min = 0
start_reduce_epsilon = 1000
train_freq = 10
update_target_q_freq = 20
n_epoch = 1000
n_max_steps = 200
last_rewards = np.zeros(n_epoch)
for epoch in range(n_epoch):
pobs = env.reset()
pobs = np.identity(n_obs, dtype=np.float32)[pobs,:].reshape((1,n_obs))
done = False
for step in range(n_max_steps):
# select action by epsilon-greedy
pact = env.action_space.sample()
if np.random.rand() > epsilon:
a = q.Q_func(Variable(pobs))
pact = np.argmax(a.data[0])
# step
obs, reward, done, _ = env.step(pact)
obs = np.identity(n_obs, dtype=np.float32)[obs,:].reshape((1,n_obs))
# stock experience
memory.append([pobs, pact, reward, obs, done])
if len(memory) > memory_size:
memory.pop(0)
# train
if len(memory) >= memory_size:
if total_step % train_freq == 0:
# replay experience
np.random.shuffle(memory)
memory_idx = range(len(memory))
for idx in memory_idx[::batch_size]:
batch = memory[idx:idx+batch_size]
pobss, pacts, rewards, obss, dones = [], [], [], [], []
for b in batch:
pobss.append(b[0].tolist())
pacts.append(b[1])
rewards.append(b[2])
obss.append(b[3].tolist())
dones.append(b[4])
pobss = np.array(pobss, dtype=np.float32)
pacts = np.array(pacts, dtype=np.int8)
rewards = np.array(rewards, dtype=np.float32)
obss = np.array(obss, dtype=np.float32)
dones = np.array(dones, dtype=np.bool)
Q = q.Q_func(Variable(pobss))
tmp = target_q.Q_func(Variable(obss))
tmp = list(map(np.max, tmp.data))
max_Q_dash = np.asanyarray(tmp, dtype=np.float32)
target = np.asanyarray(copy.deepcopy(Q.data), dtype=np.float32)
for i in range(batch_size):
target[i, pacts[i]] = rewards[i]+gamma*max_Q_dash[i]*(not dones[i])
q.zerograds()
loss = F.mean_squared_error(Q, Variable(target))
loss.backward()
optimizer.update()
if total_step % update_target_q_freq == 0:
target_q = copy.deepcopy(q)
# reduce epsilon
if epsilon > epsilon_min and total_step > start_reduce_epsilon:
epsilon -= epsilon_decrease
# update last reward
last_rewards[epoch] = reward
total_step += 1
pobs = obs
if done:
break
#print("\t".join(map(str,[epoch, epsilon, loss, reward, total_step])))
rates = np.average(last_rewards.reshape([n_epoch//10, 10]), axis=1)
plt.plot(rates)
plt.savefig("result.png")
if __name__=="__main__":
main()
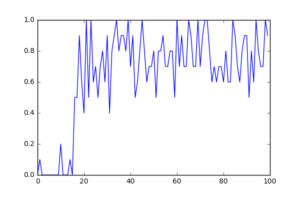
無事、学習しているようです。
問題が離散だからまだ処理が出来ましたが、これが例えばDeepMind社のようにAtariのゲームとなって、状態をゲーム画面(画像)として入力する(畳み込みニューラルネットワーク)となると、いよいよマシンスペックの問題になってきます。
さて、どうしたものか...。
追記(2017-09-07)
上記はニューラルネットワークでしたが、Atariの論文ではCNNでしたので、同じ問題ですが、無理やりCNNにしてみて実装してみました。
下記がコードになります。
GitHub: https://github.com/Gin04gh/open_ai_gym/blob/master/DQN_CNN_FrozenLake.ipynb
上記移設しました。
GitHub: https://github.com/Gin04gh/datascience/blob/master/open_ai/ddqn_cnn_frozenlake.ipynb
問題なく学習していそうです。
追記(2017-10-15)
PyTorchによる実装になりますが、連続値のゲームに対してもDQNを実装してみました。
DQNからさらに改善された研究についても少し勉強してみました。
コメント