Pythonでクロール・スクレイピングをする練習がしたかっただけなんですが、ただスクレイピングするだけじゃ面白くないので、付け足しで遊んでみました。
本当はこれでコーパスを作って、自然言語系でディープラーニングをやりたいという目的はあるのですが...。
英語単語集めるだけであれば、すでに下記のようなコーパスもありますし。
ということで遠回りにはなりますが、今回は英語文献をスクレピングする練習をしてみて、それぞれの英単語の文字の遷移を調べて、可視化してみます。
可視化グラフに関しては、Chord Diagramを利用します。
Chord Diagramの特徴
綺麗です←
特徴としては、あるシステムを構成する要素同士の関係を全体的に可視化することができます。
下記がD3.jsでの実装例のページになります。
- https://bl.ocks.org/mbostock/1046712
ビジュアルが糸玉みたいな見た目からか、書籍の『データビジュアライゼーションのデザインパターン20』では、「毛糸玉ダイアグラム」という名前で紹介されています。

名前の「Chord」も「楽器などの弦」という意味があるそうです。
今回は遷移データですが、上記のように複数の要素同士の関係を表す数値データを可視化しますので、例えば、クロス表になるデータなどでもChord Diagramに可視化することが可能です。
Pythonのクロール・スクレピングライブラリ「Scrapy」
今回はPythonのクロール・スクレイピングのライブラリ、Scrapyを使ってみます。
Scrapy : https://scrapy.org/
かなりがっちりとフレームワーク化されているライブラリで、クロール・スクレイピングを1プロジェクトとして構成するようなイメージになります。
そのためか、プロジェクトファイルの中に、コントローラーみたいな感じでクロール担当のスクリプトを書いて、クラスでデータを保持するといった書き方をしますので、個人的には、初学者には少し取っ付きづらい印象があるのかなと思います。
以前、当サイトでRubyのクロール・スクレイピングのライブラリ「Anemone」を利用したことがありましたが、こちらの方が直感的に書きやすいと思います。
Anemone : http://anemone.rubyforge.org/
また、PHPのクロール・スクレイピングのライブラリ「Goutte」も利用したことがありますが、こちらはもっと機能をパーツとして提供する感じで、どちらかといえば、Pythonの別のスクレイピングライブラリである「Beautiful Soup」とかと使い勝手は似ている印象です。
Goutte : https://github.com/FriendsOfPHP/Goutte
Beautiful Soup : https://www.crummy.com/software/BeautifulSoup/bs4/doc/
色々と規模の異なるライブラリが揃っていますので、使う場面に応じて、ライブラリを選べると良いと思います。
今回は、Scrapyをまだ使ったことがありませんでしたので、試しに使ってみることにしました。
可視化するデータの説明
大したことはしませんが、英語の文献から単語を収集してきて、アルファベットに分解した時に、どの文字からどの文字に遷移されているかを集計したものを可視化してみます。
例えば「data」という文字であれば
- d -> a
- a -> t
- t -> a
- a -> eos
といった感じです。
eosは単語の末尾を表します。
これを、ある程度の単語量を取得して、集計します。
下記のような集計テーブルがあって、各セルに、列の文字から各行の文字に遷移している数が入るイメージですね。
| a | b | c | ... | x | y | z | |
| a | |||||||
| b | |||||||
| c | |||||||
| ... | |||||||
| x | |||||||
| y | |||||||
| z | |||||||
| eos |
クロール・スクレピング実装
それでは、Scrapyでクロール・スクレイピングをして英語文章データを収集するプログラムを作成してみます。
今回はニュースサイトの「The Japan Times」から適当に記事をクロールすることにします。
The Japan Times : http://www.japantimes.co.jp/
下記コマンドで、Scrapyをインストールして、プロジェクトを作成します。
プロジェクト名は「the_japan_times」としました。
最後のコマンドは生成ファイルやディレクトリの確認をしています。
[user$host] pip install scrapy
[user$host] scrapy startproject the_japan_times
[user$host] cd the_japan_times
[user$host] basename `pwd`;find . | sort | sed '1d;s/^\.//;s/\/\([^/]*\)$/|--\1/;s/\/[^/|]*/| /g'
the_japan_times
|--scrapy.cfg
|--the_japan_times
| |--__init__.py
| |--__pycache__
| |--items.py
| |--middlewares.py
| |--pipelines.py
| |--settings.py
| |--spiders
| | |--__init__.py
| | |--__pycache___
以下のファイルを次のように編集します。
[user$host] vim the_japan_times/items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class TheJapanTimesItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
contents = scrapy.Field()
このファイルで、スクレイピングをしてどのような情報を取ってくるのかを設定します。
今回は英文ニュース記事の内容を取得する想定で、「title(記事のタイトル)」と「contents(記事の文章)」を設定しました。
次にクローラーを作成します。
[user$host] scrapy genspider thejapantimes www.japantimes.co.jp
これで、ドメイン「www.japantimes.co.jp」をクロールするクローラー「thejapantimes」を作成するという意味になります。
生成されたクローラーのファイルを編集します。
[user$host] vim the_japan_times/spiders/thejapantimes.py
# -*- coding: utf-8 -*-
import scrapy
from the_japan_times.items import TheJapanTimesItem
class ThejapantimesSpider(scrapy.Spider):
name = "thejapantimes"
allowed_domains = ["www.japantimes.co.jp"]
start_urls = ['http://www.japantimes.co.jp/']
def parse(self, response):
for sel in response.css("div.main_content div.column_small.column_large_small_margin article"):
next_page = sel.css("header h1 a::attr('href')")
if next_page:
url = response.urljoin(next_page.extract_first())
yield scrapy.Request(url, callback=self.article_parse)
def article_parse(self, response):
for sel in response.css("div.main article"):
article = TheJapanTimesItem()
article["title"] = sel.css("div.padding_block header hgroup h1::text").extract_first()
article["contents"] = sel.css("div.entry p::text").extract() # 同じ階層にpタグが複数存在するので、あるだけ(全文)取得する
yield article
next_pageにトップページの左側に並んでいるニュース記事のTOP NEWSのリンクを取得して格納しています。
リンクが存在すれば、リクエストし、コールバック関数としてarticle_parseを呼び出します。
その中でTheJapanTimesItemクラスを作成して、先ほど設定した変数に、それぞれ記事タイトルと本文を格納して保存するといった実装になります。
これでクロール・スクレイピングが可能になりましたが、実行をする前に設定ファイルを開いて、少し編集しておきます。
[user$host] vim the_japan_times/settings.py
(略)
DOWNLOAD_DELAY = 3 # コメントアウトを外す
(略)
上記の変数で、クローラーが各ページをダウンロードする間隔を秒単位で指定できます。
デフォルトではコメントアウトされていますが、クロール先のページにも迷惑をかけないように、コメントアウトを外しておきます。
これで準備が完了しました。
下記コマンドで実行します。
-oオプションにファイル名を指定してスクレイピングしたデータをファイルに保存できます。
オプション無しで実行すれば標準出力で結果を確認できます。
ファイル名には、拡張子まで指定をすることで、その形式でスクレイピングしてきたデータを保存してくれます。
csv、json、jl、xmlに対応しています。
[user$host] scrapy crawl thejapantimes -o result.json
[user$host] cat result.json
[
{"title": "Government enacts record-high budget, damping opposition efforts to keep spotlight on school land scandal", "contents": ["With Monday\u2019s passage of the record-high budget for fiscal 2017, the government of Prime Minister Shinzo Abe is headed for the latter half of the year\u2019s ordinary Diet session that, in all likelihood, promises a further war of words with opposition parties over the ongoing scandal involving a shady land deal.", "The Upper House plenary session approved the \u00a597.45 trillion budget that highlighted an increase in defense spending \u2014 a record \u00a55.13 trillion \u2014 reflecting Abe\u2019s beefed-up effort to counter China\u2019s maritime assertiveness and North Korea\u2019s missile launches. Roughly a third of the total expenditure, or \u00a532.47 trillion, is earmarked for social security costs, including pensions and medical expenses.", "The enactment of the budget will bring to a halt deliberation at budget committees \u2014 venues used by opposition forces to grill Abe and nationalist Osaka school operator Yasunori Kagoike over a heavily discounted land deal that has raised allegations of influence-peddling.", "As budget committees are practically the only place where Abe engages in spontaneous televised exchanges with his political foes, the end of the deliberations at the panels represents \u201ca significant loss of opportunity for the opposition to publicly grill him,\u201d Norihiko Narita, a political science professor at Surugadai University in Saitama Prefecture, said.", "With the budget\u2019s passage, \u201cAbe and the (ruling) Liberal Democratic Party are surely now feeling like their job is over,\u201d he said.", "Hakubun Shimomura, vice secretary-general of the LDP, expressed hope that the budget\u2019s enactment will bring some closure to the ongoing political wrangling over the scandal, which has marred the popularity of Abe\u2019s administration.", "\u201cThis ordinary Diet session is full of important bills to discuss and it\u2019s time for us to move on to the next stage,\u201d Shimomura is quoted by domestic media as saying on Sunday. Among these bills is a state-backed bill allowing crackdowns on groups that conspire to engage in serious criminal activity.", "Despite a wrap-up of the budget committee deliberations, debate over the land scandal involving ultra-nationalist school firm Moritomo Gakuen, however, will likely be carried over at a hodgepodge of less prominent Diet committees, including those on Cabinet matters and financial affairs.", "The opposition could try to pursue the matter at smaller panels, but, unlike budget committees, discussions at these venues are not televised nationally. Coupled with the fact that Abe is rarely summoned to speak at those committees in the first place, this means opposition parties will be hard-pressed to keep the issue in the spotlight, Narita said.", "\u201cThe question is now whether the opposition can stay aggressive enough not to let the momentum die off, and dig up a further piece of scandal that keeps the public interested,\u201d Narita said.", "The main opposition Democratic Party, for its part, is in no mood to afford the ruling party a chance to move on with a clean slate, adamant it will further pursue the Moritomo Gakuen saga.", "Speaking to reporters in Niigata Prefecture on Sunday, DP Secretary-General Yoshihiko Noda made it clear that his party has no intention of letting go of the matter just yet.", "\u201cIn order to achieve a true breakthrough, it is imperative that all persons involved be summoned to the Diet as sworn witnesses \u2014 and that includes Ms. Abe,\u201d Noda said in a video clip uploaded by the party.", "He was referring to first lady Akie Abe, whose secretary is said to have negotiated on her behalf \u2014 at the request of Kagoike \u2014 with the Finance Ministry in 2015 to get the school principal a special deal for his land lease. Opposition parties say that if Saeko Tani, the secretary, made inquiries to the ministry in the place of someone as influential as the first lady, it could be interpreted as pointing to Akie Abe\u2019s involvement in the land deal.", "The Moritomo Gakuen saga has dominated domestic headlines for weeks now and support rates have fallen for Abe\u2019s Cabinet. But most opinion polls show that despite the setback, the administration\u2019s popularity remains higher than 50 percent \u2014 52.4 percent, 56 percent and 62 percent, according to recent surveys by Kyodo News, Yomiuri Shimbun and the Nikkei business daily/TV Tokyo, respectively.", "Kazuhisa Kawakami, a professor of political science at the International University of Health and Welfare, attributed these results partly to voter distrust of Kagoike, who came under fire for filing three different estimates for construction costs for the planned elementary school. But more fundamentally, the administration\u2019s positive approval ratings may also reflect the lack of a viable alternative to Abe and the LDP.", "The Democratic Party, the main opposition force, struggles with a perpetually lackluster approval rating of around eight percent.", "\u201cI think there is this innate fear among the public that should the Abe government collapse, few can exert stronger leadership than Abe in dealing with issues including Trump, Putin and an increasingly uncontrollable North Korea,\u201d Kawakami said."]},
{"title": "Toshiba seeks support from Korea Electric Power Corp. as Westinghouse nuclear unit prepares for bankruptcy", "contents": ["Embattled Toshiba Corp. is seeking support from Korea Electric Power Corp. as it prepares for a Chapter 11 bankruptcy filing by its U.S. nuclear unit Westinghouse Electric Co., sources close to the matter said Monday.", "Westinghouse is expected to meet with U.S. utilities and other stakeholders to explain the Chapter 11 petition. The technology conglomerate also plans to hold a board meeting in the near future to approve the bankruptcy filing.", "By having Westinghouse file Chapter 11 by the end of this month, Toshiba is looking to finalize losses related to the U.S. nuclear unit as part of its restructuring steps.", "Toshiba said last month it had forecast more than \u00a5700 billion in losses for the April-December period in connection with its U.S. nuclear operations. But as the amount of losses could swell further, Toshiba has been mulling ways to separate itself from the fallout at Westinghouse, which it bought in 2006 to export nuclear reactors.", "Still, the filing for bankruptcy protection could increase the already huge losses linked to its U.S. nuclear business to around \u00a51 trillion.", "Westinghouse\u2019s envisioned pursuit of support from the South Korean public utility firm may not proceed smoothly, as Seoul may shift its pro-nuclear power policy in the event of a victory by former main opposition party leader Moon Jae-in in the country\u2019s upcoming presidential election in May. Westinghouse and Korea Electric have formed a technological collaboration.", "The former leader of the Democratic Party of Korea is considered a prime candidate to replace Park Geun-hye, who was ousted from office over a corruption and abuse-of-power scandal.", "Toshiba said it would try to sell Westinghouse, once lauded as the future of its atomic business, after the 2011 Fukushima disaster sidelined new orders in Japan.", "Japanese financial regulators have given the company until April 11 to publish results for the October-December quarter, which were originally due in mid-February.", "Toshiba has twice delayed releasing the figures, saying it needed more time to probe claims of misconduct by senior managers at Westinghouse and gauge the impact on its finances.", "Toshiba previously warned it was on track to report a net loss of \u00a5390 billion in the fiscal year to March, as it faced a writedown topping \u00a5700 billion at Westinghouse.", "This month Standard & Poor\u2019s cut its credit rating for Toshiba again, warning that its finances were quickly worsening.", "The Chapter 11 filing could also have international political ramifications by burdening U.S. taxpayers, given the U.S. government\u2019s debt guarantees for nuclear plant projects involving Westinghouse.", "Cash-strapped Toshiba also plans to spin off its profitable chip business and sell a majority stake of the operation to bolster its financial standing."]},
{"title": "Body of Vietnamese girl in Chiba believed abandoned after she was killed elsewhere", "contents": ["A 9-year-old girl whose body was found near a drainage ditch in Chiba Prefecture on Sunday appears to have been strangled, police said Monday as they continued a murder investigation.", "Police believe the body of the Vietnamese girl, Le Thi Nhat Linh, was dumped at the spot where it was found Sunday in Abiko after the victim was murdered elsewhere, as there were no signs of a struggle in the grass field, an investigative source said.", "Investigators also said Linh might have been kidnapped within a few minutes of leaving her home in Matsudo.", "A woman who works as a volunteer watching children along school routes was at a halfway point between Linh\u2019s home and the elementary school on Friday morning, but she did not see the girl that day, according to sources which included Matsudo\u2019s Board of Education.", "According to the police, the naked body of the girl was found by a fisherman but there were no clothes or other belongings at the site. Items belonging to her, including her school bag, have so far not been found.", "The body, already in a state of rigor mortis, was discovered in a narrow space under a bridge over the drainage ditch. Police believe the perpetrator attempted to delay its discovery, the source said. Not many people usually pass by the area.", "Police will conduct an autopsy to determine the cause of death. They will also check security cameras around the area for clues about how she disappeared on the way to elementary school last Friday morning.", "On Monday morning, police erected checkpoints on streets near the school, asking motorists whether they saw the girl on Friday morning and also requesting they provide footage from in-vehicle recorders.", "The girl, who lived in the nearby city of Matsudo, did not show up at school Friday, the last day of the school year for Japanese schools, which run from April to March. The site where she was found is about 10 km (6 miles) from the school.", "A road the girl may have taken to school includes a relatively unused section obscured by a 3-meter-high (10-foot) net to guard a pear orchard on both sides.", "In a school zone, some residents usually stand at intersections to keep their eyes on students. But so far police have not been able to locate any residents who saw her on Friday. She is believed to have walked to school by herself.", "\u201cI was worried because there are few people around the pear orchard,\u201d a housewife living in the area said."]},
{"title": "Avalanche at Tochigi ski resort leaves eight dead", "contents": ["Seven students and one teacher from Otawara High School in Tochigi Prefecture died Monday after being caught in an avalanche at a ski resort during a climbing event in the town of Nasu, an official with the Tochigi Prefectural Police said.", "The police official said 40 people were injured, adding that the department received an emergency call alerting it to the avalanche at Nasuonsen Family Ski Resort at around 9:20 a.m.", "The incident occurred around 8:30 a.m., as 40 students and eight teachers were training to walk in the accumulated snow.", "The town of Nasu received 33 cm of snow over an eight-hour period through 9 a.m. as of Monday morning, and avalanche warnings were in effect.", "The ski resort concluded operations for the season last week.", "The police are looking into whether the deaths resulted from professional negligence given the extreme conditions at the time the training was being conducted.", "The Tochigi education board said 51 students in mountaineering clubs and 11 teachers from seven high schools were participating in the climbing lesson event that began on Saturday.", "The board also said the students were scheduled to ascend the mountain on Monday, but the climb was canceled due to the heavy snow. Instead, the group practiced walking in the accumulated snow.", "The training took place about 500 meters from their hotel at an altitude of 1,300 meters.", "The avalanche occurred on the upper part of the slope."]}
]
おお、長い長い。
記事のタイトルと本文を取得できました。
Scrapyは他にも色々と運用の仕方を考慮して設計することができますが、今回はデータだけ取れれば良いので、Scrapyの出番はここまでで十分です。
後はこれを適当に単語に切り分けて、カウントしてあげて、入れ子の配列の形式で保存してあげます。
import json, re, os
# ファイル入力
result_files = [
./the_japan_times/result.json
]
words = [] # 全単語を入れる配列
for path in result_files:
f = open(path, "r")
j = json.load(f)
for d in j:
for p in d["contents"]:
p = re.sub("((?![a-z]|[A-Z]|\s).)*", "", p) # a-z,A-Z以外を削除する
p = p.lower() # 小文字にする
p = p.split(" ") # 単語の配列にする
words += p # 配列ごと追加
f.close()
print("word count: {}".format(len(words)))
# 集計テーブルの作成
data = {}
for i in range(ord("a"), ord("z")+1): # a-zまでループ
data[chr(i)] = {}
for j in range(ord("a"), ord("z")+1):
data[chr(i)][chr(j)] = 0
data[chr(i)][""] = 0
# アルファベットの遷移を集計
st_cnt = 0
for word in words:
st_cnt += len(word)
for i in range(len(word)):
if i == len(word)-1:
data[word[i]][""] += 1
else:
data[word[i]][word[i+1]] += 1
#print(data)
print("chara cnt: {}".format(st_cnt))
# 遷移マトリクスの作成
m = []
for st in data:
row = []
for i in data[st]:
row.append(data[st][i])
m.append(row)
#print(m)
# ファイル出力
f = open("./result_matrix.json", "w")
json.dump(m, f, ensure_ascii=False, indent=4, sort_keys=True, separators=(',', ': '))
f.close()
word count: 8024 chara cnt: 39517
適当に何日かに分けてニュース記事の文字を取得したところ、単語数8,000語程度、文字数にすると約40,000文字集まりました。
これらの遷移の様子をD3.jsで可視化します。
可視化の実装
ファイルはJSONで出力しましたので、同じくd3.jsonメソッドで読み込みます。(eosの分の行を入れるのを忘れていたので、こちらで無理矢理入れ込みました)
実は今までずっとバージョン3でのコーディングでしたので、バージョン4で作ることに。
微妙によく使うメソッドの名前が変更されていて少々面倒臭かったですが、そこまで大きな変更ではないみたいで良かったです。
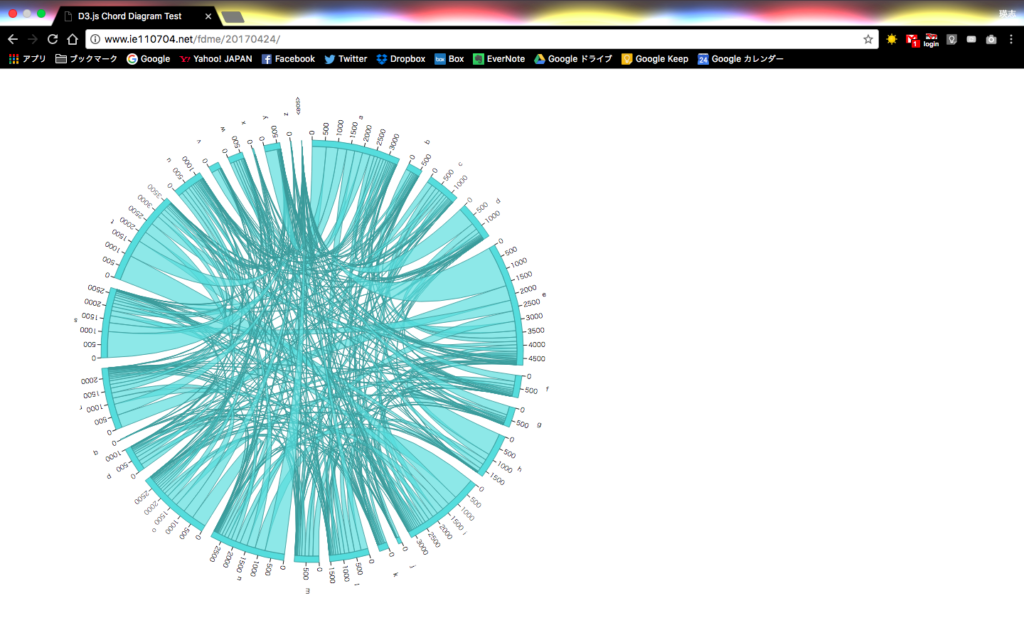
※画像をクリックするとページを移動します。
<!DOCTYPE html>
<html>
<meta charset="utf-8">
<title>D3.js Chord Diagram Test</title>
<style>
body {
font: 10px sans-serif;
}
.group-tick line {
stroke: #000;
}
.ribbons {
fill-opacity: 0.67;
}
</style>
<script>
function init(){
var matrix = []
d3.json("result_matrix.json", function(error, root){
matrix = root;
eos_row = [];
for(i=0; i<27; i++){
eos_row.push(0);
}
matrix.push(eos_row);
draw(matrix);
});
function draw(matrix){
var label = [];
for(i=97; i<= 122; i++){
label.push(String.fromCharCode(i));
}
label.push("<eos>");
var color = "#55dddd";
var svg = d3.select("svg");
var width = svg.attr("width");
var height = svg.attr("height");
var outerRadius = Math.min(width, height) * 0.5 - 100;
var innerRadius = outerRadius - 10;
var chord = d3.chord()
.padAngle(0.05)
.sortSubgroups(d3.descending);
var data = chord(matrix);
var arc = d3.arc()
.innerRadius(innerRadius)
.outerRadius(outerRadius);
var ribbon = d3.ribbon()
.radius(innerRadius);
var g = svg.append("g")
.attr("transform", "translate(" + width / 2 + "," + height / 2 + ")")
.datum(data);
var group = g.append("g")
.attr("class", "groups")
.selectAll("g")
.data(function(chords) { return chords.groups; })
.enter().append("g");
group.append("path")
.style("fill", color)
.style("stroke", d3.rgb(color).darker())
.attr("d", arc)
.on("mouseover", fade(.1))
.on("mouseout", fade(1));
var groupTick = group.selectAll(".group-tick")
.data(function(d) { return groupTicks(d, 5e2); })
.enter().append("g")
.attr("class", "group-tick")
.attr("transform", function(d) { return "rotate(" + (d.angle * 180 / Math.PI - 90) + ") translate(" + outerRadius + ",0)"; })
groupTick.append("line")
.attr("x2", 6)
groupTick.filter(function(d) { return d.value % 5e2 === 0; })
.append("text")
.attr("class", "val")
.attr("x", 8)
.attr("dy", ".35em")
.text(function(d) { return d.value; });
group.append("text")
.attr("class", "label")
.attr("x", 40)
.attr("transform", function(d) { return "rotate(" + (((d.startAngle + d.endAngle) / 2) * 180 / Math.PI - 90) + ") translate(" + outerRadius + ",0)"; })
.text(function(d) { return label[d["index"]]; });
g.select("g.groups")
.append("g")
.attr("class", "ribbons")
.selectAll("path")
.data(function(chords) { return chords; })
.enter().append("path")
.attr("d", ribbon)
.style("fill", color)
.style("stroke", d3.rgb(color).darker());
// Returns an array of tick angles and values for a given group and step.
function groupTicks(d, step) {
var k = (d.endAngle - d.startAngle) / d.value;
return d3.range(0, d.value, step).map(function(value) {
return { value: value, angle: value * k + d.startAngle };
});
}
// Returns an event handler for fading a given chord group.
function fade(opacity) {
return function(g, i) {
svg.selectAll("g.groups g.ribbons path")
.filter(function(d) { return d.source.index != i && d.target.index != i; })
.transition()
.style("opacity", opacity);
};
}
}
}
</script>
</head>
<body onload="javascript:init();">
<svg width="960" height="960"></svg>
</body>
</html>
綺麗ですけど、ちょっと見づらくなってしまいました。
結構思った通りといいますか、「z」とか全く出てきませんね。
よく末尾となる文字は、「d」「e」「s」「t」「y」といった感じみたいです。
一応、弧にマウスオーバーすることで、どの文字から遷移してきているかを透過で分かるようにしましたが、eosから始まるものは当然ないから、eosの弧にマウスを乗せるのが非常に難しくなっております笑
コメント