RNNの実装の勉強もしました。
今回は整理と備忘録も込めて、Chainerでニューラルネットワーク、リカレントニューラルネットワーク、畳み込みニューラルネットワークの実装について記します。
ニューラルネットワーク(Neural network; NN)
順伝播型のニューラルネットワークです。
簡単な練習問題として、アイリスのデータを分類するモデルを書きました。
ニューラルネットワークを使うまでもない問題ですが、実装の仕方の勉強のため、基本的な問題にしました。
各コードでやっていることを理解すると、別の問題も書くことができますし、他のニューラルネットワークへの参入もグッと楽になりました。
ChainerによるNNの実装1
ニューラルネットワークの実装です。
GitHub: https://github.com/Gin04gh/samples_py/blob/master/NeuralNetwork_Chainer_ver1.ipynb
移設しました。(コードも更新)
GitHub: https://github.com/Gin04gh/datascience/blob/master/samples_deeplearning_python/nn_chainer_ver1.ipynb
import time
import numpy as np
import pandas as pd
from sklearn import datasets
from chainer import Chain, Variable, cuda, optimizer, optimizers, serializers
import chainer.functions as F
import chainer.links as L
# モデルクラス定義
class NN(Chain):
def __init__(self, in_size, hidden_size, out_size):
# クラスの初期化
# :param in_size: 入力層のサイズ
# :param hidden_size: 隠れ層のサイズ
# :param out_size: 出力層のサイズ
super(NN, self).__init__(
xh = L.Linear(in_size, hidden_size),
hh = L.Linear(hidden_size, hidden_size),
hy = L.Linear(hidden_size, out_size)
)
def __call__(self, x, y=None, train=False):
# 順伝播の計算を行う関数
# :param x: 入力値
# :param t: 正解のラベル
# :param train: 学習かどうか
# :return: 計算した損失 or 予測したラベル
x = Variable(x)
if train:
y = Variable(y)
h = F.sigmoid(self.xh(x))
h = F.sigmoid(self.hh(h))
y_ = F.softmax(self.hy(h))
if train:
loss, accuracy = F.softmax_cross_entropy(y_, y), F.accuracy(y_, y)
return loss, accuracy
else:
return np.argmax(y_.data)
def reset(self):
# 勾配の初期化
self.zerograds()
# 学習
EPOCH_NUM = 100
HIDDEN_SIZE = 20
BATCH_SIZE = 20
# データ
N = 100
in_size = 4
out_size = 3
iris = datasets.load_iris()
data = pd.DataFrame(data= np.c_[iris["data"], iris["target"]], columns= iris["feature_names"] + ["target"])
data = np.array(data.values)
perm = np.random.permutation(len(data))
data = data[perm]
train, test = np.split(data, [N])
train_x, train_y, test_x, test_y = [], [], [], []
for t in train:
train_x.append(t[0:4])
train_y.append(t[4])
for t in test:
test_x.append(t[0:4])
test_y.append(t[4])
train_x = np.array(train_x, dtype="float32")
train_y = np.array(train_y, dtype="int32")
test_x = np.array(test_x, dtype="float32")
test_y = np.array(test_y, dtype="int32")
# モデルの定義
model = NN(in_size=in_size, hidden_size=HIDDEN_SIZE, out_size=out_size)
optimizer = optimizers.Adam()
optimizer.setup(model)
# 学習開始
print("Train")
st = time.time()
for epoch in range(EPOCH_NUM):
# ミニバッチ学習
perm = np.random.permutation(N) # ランダムな整数列リストを取得
total_loss = 0
total_accuracy = 0
for i in range(0, N, BATCH_SIZE):
x = train_x[perm[i:i+BATCH_SIZE]]
y = train_y[perm[i:i+BATCH_SIZE]]
model.reset()
loss, accuracy = model(x=x, y=y, train=True)
loss.backward()
loss.unchain_backward()
total_loss += loss.data
total_accuracy += accuracy.data
optimizer.update()
if (epoch+1) % 10 == 0:
ed = time.time()
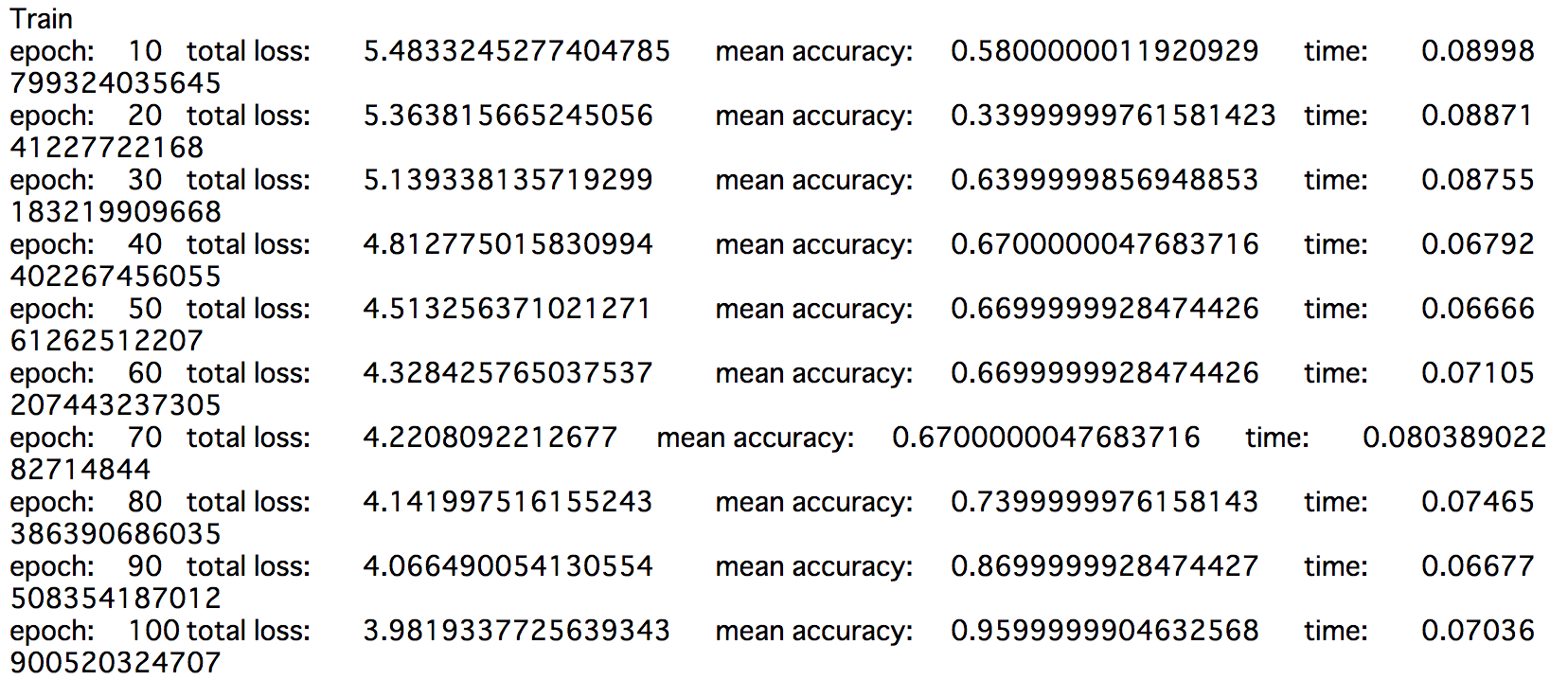
print("epoch:\t{}\ttotal loss:\t{}\tmean accuracy:\t{}\ttime:\t{}".format(epoch+1, total_loss, total_accuracy/(N/BATCH_SIZE), ed-st))
st = time.time()
# 予測
print("Predict")
res = []
for x, y in zip(test_x, test_y):
y_ = model(x=x.reshape(1,len(x)), train=False)
if y == y_:
res.append(1)
else:
res.append(0)
accuracy = sum(res)/len(res)
print("test data accuracy: ", accuracy)

ChainerによるNNの実装2(classifier、training使用)
今はclassifierクラス、trainingクラスを使用も推奨されていますので、同じ問題で実装したコードも記します。
GitHub: https://github.com/Gin04gh/samples_py/blob/master/NeuralNetwork_Chainer_ver2.ipynb
移設しました。
GitHub: https://github.com/Gin04gh/datascience/blob/master/samples_deeplearning_python/nn_chainer_ver2.ipynb
import time
import numpy as np
import pandas as pd
from sklearn import datasets
import chainer
from chainer import Chain, optimizers, training
from chainer.training import extensions
import chainer.functions as F
import chainer.links as L
# モデルクラス定義
class NN(Chain):
def __init__(self, in_size, hidden_size, out_size):
# クラスの初期化
# :param in_size: 入力層のサイズ
# :param hidden_size: 隠れ層のサイズ
# :param out_size: 出力層のサイズ
super(NN, self).__init__(
xh = L.Linear(in_size, hidden_size),
hh = L.Linear(hidden_size, hidden_size),
hy = L.Linear(hidden_size, out_size)
)
def __call__(self, x):
# 順伝播の計算を行う関数
# :param x: 入力値
h = F.sigmoid(self.xh(x))
h = F.sigmoid(self.hh(h))
y = self.hy(h)
return y
# 学習
EPOCH_NUM = 100
HIDDEN_SIZE = 20
BATCH_SIZE = 20
# データ
N = 100
in_size = 4
out_size = 3
iris = datasets.load_iris()
data = pd.DataFrame(data= np.c_[iris["data"], iris["target"]], columns= iris["feature_names"] + ["target"])
data = np.array(data.values)
dataset = []
for d in data:
x = d[0:4]
y = d[4]
dataset.append((np.array(x, dtype="float32"), np.array(y, dtype="int32")))
N = len(dataset)
# モデルの定義
model = L.Classifier(NN(in_size=in_size, hidden_size=HIDDEN_SIZE, out_size=out_size))
optimizer = optimizers.Adam()
optimizer.setup(model)
# 学習開始
print("Train")
train, test = chainer.datasets.split_dataset_random(dataset, N-50) # 100件を学習用、50件をテスト用
train_iter = chainer.iterators.SerialIterator(train, BATCH_SIZE)
test_iter = chainer.iterators.SerialIterator(test, BATCH_SIZE, repeat=False, shuffle=False)
updater = training.StandardUpdater(train_iter, optimizer, device=-1)
trainer = training.Trainer(updater, (EPOCH_NUM, "epoch"), out="result")
trainer.extend(extensions.Evaluator(test_iter, model, device=-1))
trainer.extend(extensions.LogReport(trigger=(10, "epoch"))) # 10エポックごとにログ出力
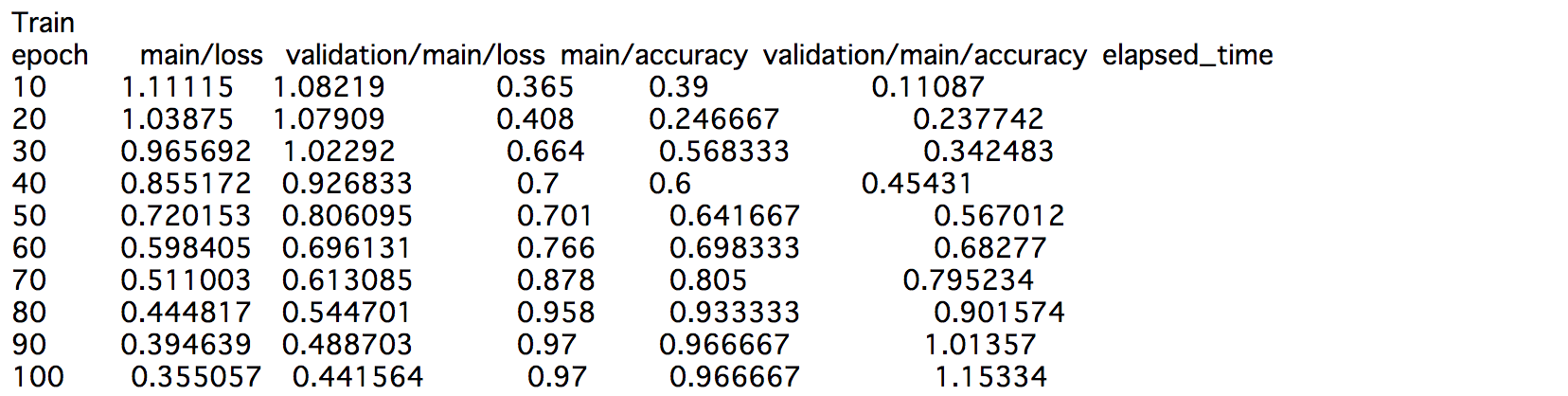
trainer.extend(extensions.PrintReport( ["epoch", "main/loss", "validation/main/loss", "main/accuracy", "validation/main/accuracy", "elapsed_time"])) # エポック、学習損失、テスト損失、学習正解率、テスト正解率、経過時間
#trainer.extend(extensions.ProgressBar()) # プログレスバー出力
trainer.run()
# 予測
print("Predict")
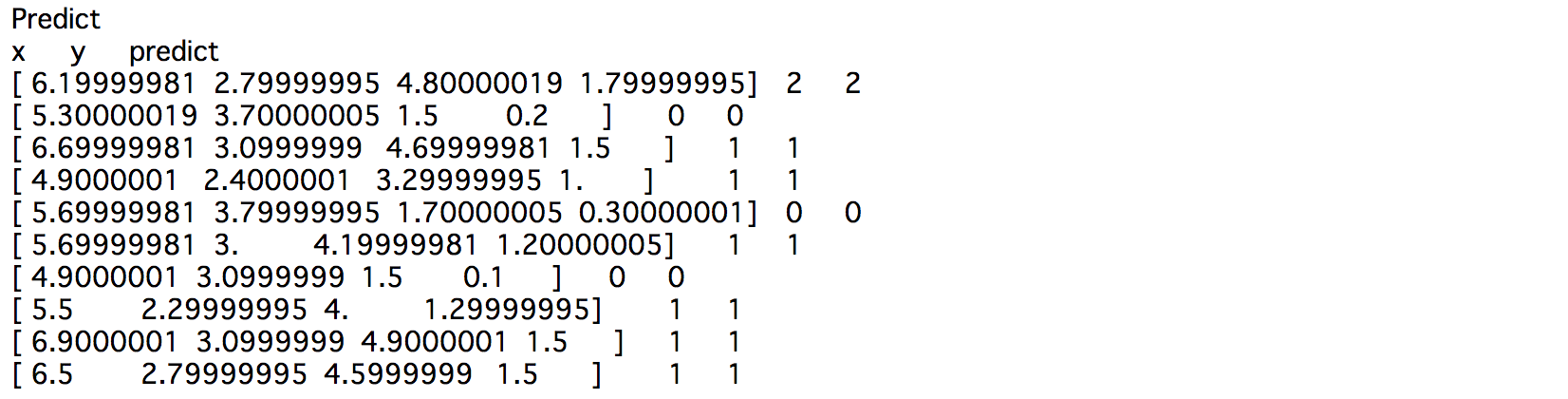
print("x\ty\tpredict")
idx = np.random.choice(N, 10)
for i in idx:
x = dataset[i][0]
y_ = np.argmax(model.predictor(x=x.reshape(1,len(x))).data)
y = dataset[i][1]
print(x, "\t", y, "\t", y_)
再帰的ニューラルネットワーク(Reccurent neural network; RNN)
系列データを扱うことに優れた構造のニューラルネットワークです。
RNNは前の時刻の隠れ層ベクトルと現時刻の入力ベクトルを使って、現在の隠れ層ベクトルを更新することで、任意の長さの入力履歴を考慮した出力を得ることができます。
詳しい説明は省略しますが、これは構造的に深い層のニューラルネットワークを学習することと同じことになり、層が深いネットワークほど、勾配爆発や勾配消失といった問題により誤差が伝播しづらくなっていくため、普通に構築しただけでは、せいぜい時系列3つ4つ前程度しか記憶しません。
これを改善するために、遠い隠れ層を直接参照できるような仕組み(ゲート)を加えたRNNが提案されています。
その隠れ層の保持の仕方なども調整するパラメータを用意して、同時に学習させることで、過去の記憶力をより向上させたRNNとしてLSTM(Long-short term memory)やGRU(Gated reccurent unit)というものがあります。
現在では、RNNといえば通常LSTMやGRUなどのゲート付きのRNNを指すことが一般的なようです。
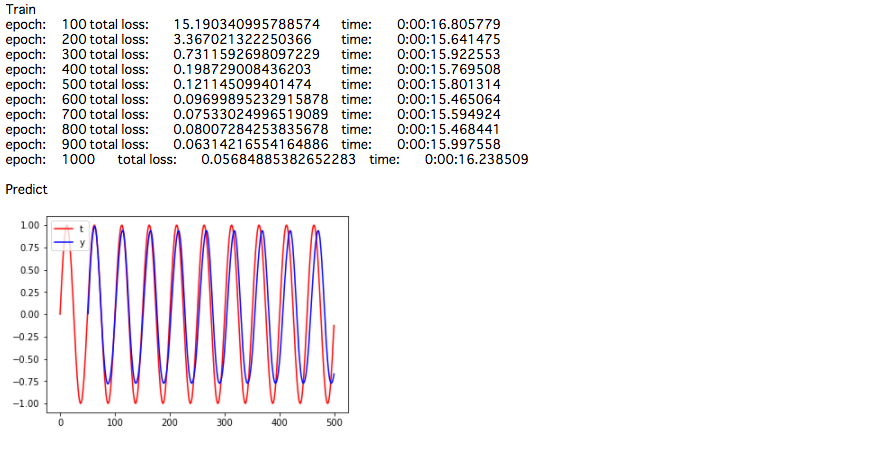
下記は、LSTMで正弦波を予測するモデルの実装になります。
ChainerによるRNN-LSTMの実装1(F.lstm)
GitHub: https://github.com/Gin04gh/samples_py/blob/master/LSTM_Chainer_ver1.ipynb
移設しました。
import datetime
import numpy as np
import matplotlib.pylab as plt
from chainer import Chain, Variable, cuda, optimizer, optimizers, serializers
import chainer.functions as F
import chainer.links as L
# モデルクラス定義
class LSTM(Chain):
def __init__(self, in_size, hidden_size, out_size):
# クラスの初期化
# :param in_size: 入力層のサイズ
# :param hidden_size: 隠れ層のサイズ
# :param out_size: 出力層のサイズ
super(LSTM, self).__init__(
xh = L.Linear(in_size, hidden_size),
hh_x = L.Linear(hidden_size, 4 * hidden_size),
hh_h = L.Linear(hidden_size, 4 * hidden_size),
hy = L.Linear(hidden_size, out_size)
)
self.hidden_size = hidden_size
def __call__(self, x, t=None, train=False):
# 順伝播の計算を行う関数
# :param x: 入力値
# :param t: 正解の予測値
# :param train: 学習かどうか
# :return: 計算した損失 or 予測値
if self.h is None:
self.h = Variable(np.zeros((x.shape[0], self.hidden_size), dtype="float32"))
self.c = Variable(np.zeros((x.shape[0], self.hidden_size), dtype="float32"))
x = Variable(x)
if train:
t = Variable(t)
h = self.xh(x)
h = self.hh_x(h) + self.hh_h(self.h)
self.c, self.h = F.lstm(self.c, h)
y = self.hy(self.h)
if train:
return F.mean_squared_error(y, t)
else:
return y.data
def reset(self):
# 勾配の初期化とメモリの初期化
self.zerograds()
self.h = None
self.c = None
# 学習
EPOCH_NUM = 1000
HIDDEN_SIZE = 5
BATCH_ROW_SIZE = 100 # 分割した時系列をいくつミニバッチに取り込むか
BATCH_COL_SIZE = 100 # ミニバッチで分割する時系列数
# 教師データ
train_data = np.array([np.sin(i*2*np.pi/50) for i in range(50)]*10)
# 教師データを変換
train_x, train_t = [], []
for i in range(len(train_data)-1):
train_x.append(train_data[i])
train_t.append(train_data[i+1])
train_x = np.array(train_x, dtype="float32")
train_t = np.array(train_t, dtype="float32")
in_size = 1
out_size = 1
N = len(train_x)
# モデルの定義
model = LSTM(in_size=in_size, hidden_size=HIDDEN_SIZE, out_size=out_size)
optimizer = optimizers.Adam()
optimizer.setup(model)
# 学習開始
print("Train")
st = datetime.datetime.now()
for epoch in range(EPOCH_NUM):
# ミニバッチ学習
x, t = [], []
# ミニバッチ学習データとして、時系列全体から、BATCH_COL_SIZE分の時系列を抜き出したものを、BATCH_ROW_SIZE個用意する
for i in range(BATCH_ROW_SIZE):
index = np.random.randint(0, N-BATCH_COL_SIZE+1) # ランダムな箇所、ただしBATCH_COL_SIZE分だけ抜き取れる場所から選ぶ
x.append(train_x[index:index+BATCH_COL_SIZE]) # BATCH_COL_SIZE分の時系列を取り出す
t.append(train_t[index:index+BATCH_COL_SIZE])
x = np.array(x, dtype="float32")
t = np.array(t, dtype="float32")
loss = 0
total_loss = 0
model.reset() # 勾配とメモリの初期化
for i in range(BATCH_COL_SIZE): # 各時刻おきにBATCH_ROW_SIZEごと読み込んで損失を計算する
x_ = np.array([x[j, i] for j in range(BATCH_ROW_SIZE)], dtype="float32")[:, np.newaxis] # 時刻iの入力値
t_ = np.array([t[j, i] for j in range(BATCH_ROW_SIZE)], dtype="float32")[:, np.newaxis] # 時刻i+1の値(=正解の予測値)
loss += model(x=x_, t=t_, train=True)
loss.backward()
loss.unchain_backward()
total_loss += loss.data
optimizer.update()
if (epoch+1) % 100 == 0:
ed = datetime.datetime.now()
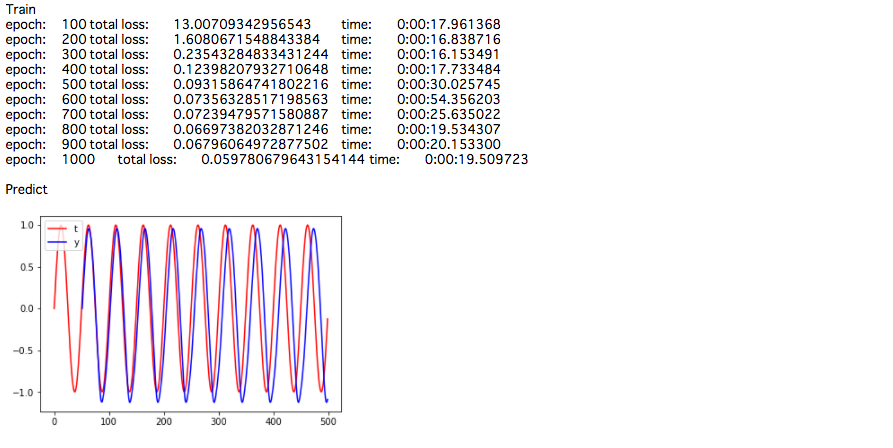
print("epoch:\t{}\ttotal loss:\t{}\ttime:\t{}".format(epoch+1, total_loss, ed-st))
st = datetime.datetime.now()
# 予測
print("\nPredict")
predict = np.empty(0) # 予測時系列
inseq_size = 50
inseq = train_data[:inseq_size] # 予測直前までの時系列
for _ in range(N - inseq_size):
model.reset() # メモリを初期化
for i in inseq: # モデルに予測直前までの時系列を読み込ませる
x = np.array([[i]], dtype="float32")
y = model(x=x, train=False)
predict = np.append(predict, y) # 最後の予測値を記録
# モデルに読み込ませる予測直前時系列を予測値で更新する
inseq = np.delete(inseq, 0)
inseq = np.append(inseq, y)
plt.plot(range(N+1), train_data, color="red", label="t")
plt.plot(range(inseq_size+1, N+1), predict, color="blue", label="y")
plt.legend(loc="upper left")
plt.show()
ChainerによるRNN-LSTMの実装2(L.LSTM)
上記の実装はLSTMのゲートがどういう構成をされているのかを理解していなければ、少し直感的にわかりづらいところもありますが、Chainerではより簡単なLSTM関数が用意されていますので、場合によればこっちの方が簡潔で良いと思います。
RNNで計算した隠れ層を別の層の入力に用いるなど、複雑なネットワーク構成にする場合は、上記のコードで理解した方が自由度が高くて扱いやすいかもしれません。
同じ問題で、LSTM関数を使った実装が下記になります。
GitHub: https://github.com/Gin04gh/samples_py/blob/master/LSTM_Chainer_ver2.ipynb
移設しました。
import datetime
import numpy as np
import matplotlib.pylab as plt
from chainer import Chain, Variable, cuda, optimizer, optimizers, serializers
import chainer.functions as F
import chainer.links as L
# モデルクラス定義
class LSTM(Chain):
def __init__(self, in_size, hidden_size, out_size):
# クラスの初期化
# :param in_size: 入力層のサイズ
# :param hidden_size: 隠れ層のサイズ
# :param out_size: 出力層のサイズ
super(LSTM, self).__init__(
xh = L.Linear(in_size, hidden_size),
hh = L.LSTM(hidden_size, hidden_size),
hy = L.Linear(hidden_size, out_size)
)
def __call__(self, x, t=None, train=False):
# 順伝播の計算を行う関数
# :param x: 入力値
# :param t: 正解の予測値
# :param train: 学習かどうか
# :return: 計算した損失 or 予測値
x = Variable(x)
if train:
t = Variable(t)
h = self.xh(x)
h = self.hh(h)
y = self.hy(h)
if train:
return F.mean_squared_error(y, t)
else:
return y.data
def reset(self):
# 勾配の初期化とメモリの初期化
self.zerograds()
self.hh.reset_state()
# 学習
EPOCH_NUM = 1000
HIDDEN_SIZE = 5
BATCH_ROW_SIZE = 100 # 分割した時系列をいくつミニバッチに取り込むか
BATCH_COL_SIZE = 100 # ミニバッチで分割する時系列数
# 教師データ
train_data = np.array([np.sin(i*2*np.pi/50) for i in range(50)]*10)
# 教師データを変換
train_x, train_t = [], []
for i in range(len(train_data)-1):
train_x.append(train_data[i])
train_t.append(train_data[i+1])
train_x = np.array(train_x, dtype="float32")
train_t = np.array(train_t, dtype="float32")
in_size = 1
out_size = 1
N = len(train_x)
# モデルの定義
model = LSTM(in_size=in_size, hidden_size=HIDDEN_SIZE, out_size=out_size)
optimizer = optimizers.Adam()
optimizer.setup(model)
# 学習開始
print("Train")
st = datetime.datetime.now()
for epoch in range(EPOCH_NUM):
# ミニバッチ学習
x, t = [], []
# ミニバッチ学習データとして、時系列全体から、BATCH_COL_SIZE分の時系列を抜き出したものを、BATCH_ROW_SIZE個用意する
for i in range(BATCH_ROW_SIZE):
index = np.random.randint(0, N-BATCH_COL_SIZE+1) # ランダムな箇所、ただしBATCH_COL_SIZE分だけ抜き取れる場所から選ぶ
x.append(train_x[index:index+BATCH_COL_SIZE]) # BATCH_COL_SIZE分の時系列を取り出す
t.append(train_t[index:index+BATCH_COL_SIZE])
x = np.array(x, dtype="float32")
t = np.array(t, dtype="float32")
loss = 0
total_loss = 0
model.reset() # 勾配とメモリの初期化
for i in range(BATCH_COL_SIZE): # 各時刻おきにBATCH_ROW_SIZEごと読み込んで損失を計算する
x_ = np.array([x[j, i] for j in range(BATCH_ROW_SIZE)], dtype="float32")[:, np.newaxis] # 時刻iの入力値
t_ = np.array([t[j, i] for j in range(BATCH_ROW_SIZE)], dtype="float32")[:, np.newaxis] # 時刻i+1の値(=正解の予測値)
loss += model(x=x_, t=t_, train=True)
loss.backward()
loss.unchain_backward()
total_loss += loss.data
optimizer.update()
if (epoch+1) % 100 == 0:
ed = datetime.datetime.now()
print("epoch:\t{}\ttotal loss:\t{}\ttime:\t{}".format(epoch+1, total_loss, ed-st))
st = datetime.datetime.now()
# 予測
print("\nPredict")
predict = np.empty(0) # 予測時系列
inseq_size = 50
inseq = train_data[:inseq_size] # 予測直前までの時系列
for _ in range(N - inseq_size):
model.reset() # メモリを初期化
for i in inseq: # モデルに予測直前までの時系列を読み込ませる
x = np.array([[i]], dtype="float32")
y = model(x=x, train=False)
predict = np.append(predict, y) # 最後の予測値を記録
# モデルに読み込ませる予測直前時系列を予測値で更新する
inseq = np.delete(inseq, 0)
inseq = np.append(inseq, y)
plt.plot(range(N+1), train_data, color="red", label="t")
plt.plot(range(inseq_size+1, N+1), predict, color="blue", label="y")
plt.legend(loc="upper left")
plt.show()
RNN-LSTMの実装における、classifierクラス、trainingクラスの使用について
RNNではバッチの形や、読み込ませ方が他のモデルと若干異なるため、IteratorクラスとUpdaterクラスを自分で改修しなければならないようです。
以下が参考です。
- https://github.com/chainer/chainer/blob/master/examples/ptb/train_ptb.py
正直、RNNを扱う機会自体そんなに多くありませんので、ここまでやる気は起きませんでしたので、実装は省略します。
またやらなければならなくなった際に勉強して、コードを追記することにします。
追記(2017-09-23)
余談ではありますが、RNNで覚えさせたベクトルを最終的に分類タスクに用いたいなどであれば、ネットワークの作り方次第で、バッチの形を他のネットワークと同じように作れますので、そのままTrainerクラスを使うことができます。
下記のLSTMの実装が参考です。
畳み込みニューラルネットワーク(convolution neural network; CNN)
順伝播型ニューラルネットワークのような全結合層だけでなく、畳み込み層とプーリング層から構成されるニューラルネットワークです。
特に画像処理の分野において成功を収めている手法です。
これも詳しくは省略しますが、画像に対して小さな窓(フィルタ)をスライドしていきながら値を取得し、集約(最大プーリングや平均プーリング)することで、画像の特徴的な部分を抽出して、それらの情報を使ってネットワークを計算します。
ChainerによるCNNの実装1
GitHub: https://github.com/Gin04gh/samples_py/blob/master/ConvolutionalNeuralNetwork_Chainer_ver1.ipynb
移設しました。(コードも更新)
import datetime
import numpy as np
import matplotlib.pylab as plt
from matplotlib import cm
from chainer import Chain, Variable, cuda, optimizer, optimizers, serializers
import chainer.functions as F
import chainer.links as L
from sklearn.datasets import fetch_mldata
# モデルクラス定義
class CNN(Chain):
def __init__(self):
# クラスの初期化
super(CNN, self).__init__(
conv1 = L.Convolution2D(None, 20, 5), # フィルター5
conv2 = L.Convolution2D(20, 50, 5), # フィルター5
l1 = L.Linear(800, 500),
l2 = L.Linear(500, 500),
l3 = L.Linear(500, 10, initialW=np.zeros((10, 500), dtype=np.float32))
)
def __call__(self, x, t=None, train=False):
# 順伝播の計算を行う関数
# :param x: 入力値
# :param t: 正解のラベル
# :param train: 学習かどうか
# :return: 計算した損失 or 予測したラベル
x = Variable(x)
if train:
t = Variable(t)
h = F.max_pooling_2d(F.relu(self.conv1(x)), 2)
h = F.max_pooling_2d(F.relu(self.conv2(h)), 2)
h = F.relu(self.l1(h))
h = F.relu(self.l2(h))
y = F.softmax(self.l3(h))
if train:
loss, accuracy = F.softmax_cross_entropy(y, t), F.accuracy(y, t)
return loss, accuracy
else:
return np.argmax(y.data)
def reset(self):
# 勾配の初期化
self.zerograds()
# 学習
EPOCH_NUM = 5
BATCH_SIZE = 1000
# 教師データ
mnist = fetch_mldata('MNIST original', data_home='.')
mnist.data = mnist.data.astype(np.float32) # 画像データ 784*70000 [[0-255, 0-255, ...], [0-255, 0-255, ...], ... ]
mnist.data /= 255 # 0-1に正規化する
mnist.target = mnist.target.astype(np.int32) # ラベルデータ70000
# 教師データを変換
N = 60000
train_x, test_x = np.split(mnist.data, [N]) # 教師データ
train_t, test_t = np.split(mnist.target, [N]) # テスト用のデータ
train_x = train_x.reshape((len(train_x), 1, 28, 28)) # (N, channel, height, width)
test_x = test_x.reshape((len(test_x), 1, 28, 28))
# モデルの定義
model = CNN()
optimizer = optimizers.Adam()
optimizer.setup(model)
# 学習開始
print("Train")
st = datetime.datetime.now()
for epoch in range(EPOCH_NUM):
# ミニバッチ学習
perm = np.random.permutation(N) # ランダムな整数列リストを取得
total_loss = 0
total_accuracy = 0
for i in range(0, N, BATCH_SIZE):
x = train_x[perm[i:i+BATCH_SIZE]]
t = train_t[perm[i:i+BATCH_SIZE]]
model.reset()
loss, accuracy = model(x=x, t=t, train=True)
loss.backward()
loss.unchain_backward()
total_loss += loss.data
total_accuracy += accuracy.data
optimizer.update()
ed = datetime.datetime.now()
print("epoch:\t{}\ttotal loss:\t{}\tmean accuracy:\t{}\ttime:\t{}".format(epoch+1, total_loss, total_accuracy/(N/BATCH_SIZE), ed-st))
st = datetime.datetime.now()
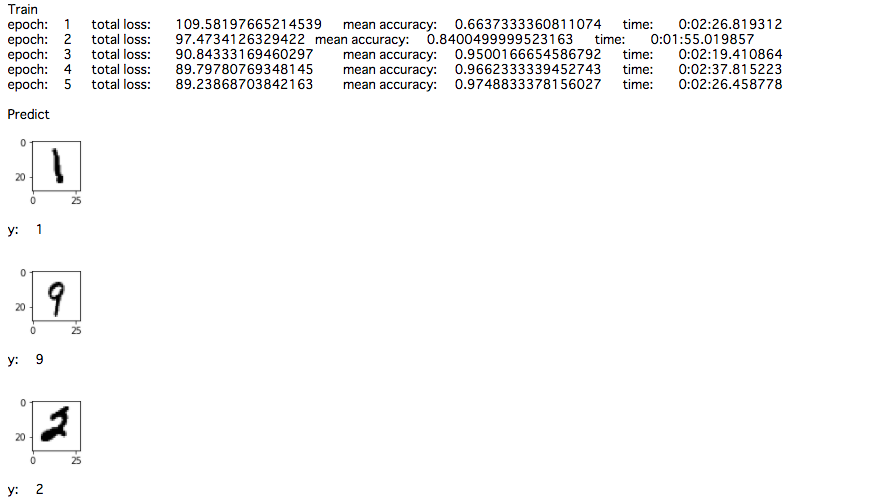
# 予測
print("\nPredict")
def predict(model, x):
y = model(x=np.array([x], dtype="float32"), train=False)
plt.figure(figsize=(1, 1))
plt.imshow(x[0], cmap=cm.gray_r)
plt.show()
print("y:\t{}\n".format(y))
idx = np.random.choice((70000-N), 10)
for i in idx:
predict(model, test_x[i])
ChainerによるCNNの実装2(classifier、training使用)
こちらもclassifierクラス、trainingクラスを使用した例を記します。
GitHub: https://github.com/Gin04gh/samples_py/blob/master/ConvolutionalNeuralNetwork_Chainer_ver2.ipynb
移設しました。(コードも更新)
import numpy as np
import matplotlib.pylab as plt
from matplotlib import cm
import chainer
from chainer import Chain, optimizers, training
from chainer.training import extensions
import chainer.functions as F
import chainer.links as L
from sklearn.datasets import fetch_mldata
# 畳み込みニューラルネットワークでMNIST画像分類 ver. classifierクラス, trainingクラス
# モデルクラス定義
class CNN(Chain):
def __init__(self):
# クラスの初期化
super(CNN, self).__init__(
conv1 = L.Convolution2D(1, 20, 5), # フィルター5
conv2 = L.Convolution2D(20, 50, 5), # フィルター5
l1 = L.Linear(800, 500),
l2 = L.Linear(500, 500),
l3 = L.Linear(500, 10, initialW=np.zeros((10, 500), dtype=np.float32))
)
def __call__(self, x):
# 順伝播の計算を行う関数
# :param x: 入力値
h = F.max_pooling_2d(F.relu(self.conv1(x)), 2)
h = F.max_pooling_2d(F.relu(self.conv2(h)), 2)
h = F.relu(self.l1(h))
h = F.relu(self.l2(h))
y = self.l3(h)
return y
# 学習
EPOCH_NUM = 5
BATCH_SIZE = 1000
# 教師データ
mnist = fetch_mldata('MNIST original', data_home='.')
mnist.data = mnist.data.astype(np.float32) # 画像データ 784*70000 [[0-255, 0-255, ...], [0-255, 0-255, ...], ... ]
mnist.data /= 255 # 0-1に正規化する
mnist.target = mnist.target.astype(np.int32) # ラベルデータ70000
# 教師データを変換
dataset = []
for x, t in zip(mnist.data, mnist.target):
dataset.append((x.reshape(1, 28, 28), t))
N = len(dataset)
# モデルの定義
model = L.Classifier(CNN())
optimizer = optimizers.Adam()
optimizer.setup(model)
# 学習開始
print("Train")
train, test = chainer.datasets.split_dataset_random(dataset, N-10000) # 60000件を学習用、10000件をテスト用
train_iter = chainer.iterators.SerialIterator(train, BATCH_SIZE)
test_iter = chainer.iterators.SerialIterator(test, BATCH_SIZE, repeat=False, shuffle=False)
updater = training.StandardUpdater(train_iter, optimizer, device=-1)
trainer = training.Trainer(updater, (EPOCH_NUM, "epoch"), out="result")
trainer.extend(extensions.Evaluator(test_iter, model, device=-1))
trainer.extend(extensions.LogReport())
trainer.extend(extensions.PrintReport( ["epoch", "main/loss", "validation/main/loss", "main/accuracy", "validation/main/accuracy", "elapsed_time"])) # エポック、学習損失、テスト損失、学習正解率、テスト正解率、経過時間
#trainer.extend(extensions.ProgressBar()) # プログレスバー出力
trainer.run()
# 予測
print("\nPredict")
def predict(model, x):
y = np.argmax(model.predictor(x=np.array([x], dtype="float32")).data)
plt.figure(figsize=(1, 1))
plt.imshow(x[0], cmap=cm.gray_r)
plt.show()
print("y:\t{}\n".format(y))
idx = np.random.choice(70000, 10)
for i in idx:
predict(model, dataset[i][0])
追記(2017-08-15)
以前に記載していた実装コードでは、optimizerの部分が、
-省略-
# モデルの定義
model = 省略
# 学習開始
print("Train")
st = datetime.datetime.now()
for epoch in range(EPOCH_NUM):
# エポックごとにoptimizerの初期化
optimizer = optimizers.Adam()
optimizer.setup(model)
# ミニバッチ学習
-省略-
としておりました。
これに対し、先日コメントで、エポックごとにoptimizerの初期化するのはなぜか、とのご質問をいただきました。
これは、私が参考にしたコードがこのようになっていたため、深く考えていませんでしたが、誤りです。
SGDなどの場合は、これでも問題ない(と思う)のですが、上記のようにAdamの場合は、その時のエポックでの学習率が、前のエポックでの誤差に依存するため、上記のようにオプティマイザーをエポックごとに初期化してしまうと、学習率が初期値から変化しなくなるため、不適切だと思います。
ネット上でも、コードが混合していますので、注意が必要です。
コメントしていただいた方、ありがとうございました。
追記(2017-08-31)
PyTorchの実装もまとめてみました。

追記(2017-10-24)
TensorFlowも実装してみました。
コメント