今回は、PyTorchでニューラルネットワーク、再帰的ニューラルネットワーク、畳み込みニューラルネットワークの実装について記します。
以前にChainerの実装をまとめたときのものと同じタスクを実装してみて、比較しやすいようにしてみました。
PyTorch
PyTorch: http://pytorch.org/
PyTorchはFacebookが開発する深層学習に特化したライブラリです。
Pythonから実行できます。
インストールは公式ページを見るとわかりやすいと思いますが、OSや環境などをポチポチ選択していけばインストールコマンドが参照できますので、それを実行するだけです。
2017年始め頃に登場したばかりですが、瞬く間にTensorFlorやKerasに続く人気の深層学習ライブラリとなっているようです。(自分の周りでは使っている人がいないですが...)
また、PyTorchは、Preferred NetworkのChainerから影響を受けているようで、Chainerと同様、計算時に動的にグラフを構築する(Define-by-Run)ライブラリです。
書き方もTensorFlowやKerasなどよりもChainer寄り、というかむしろそっくりな書き方をするのが特徴です。
PyTorchによるニューラルネットワークの実装
順伝播型ニューラルネットワークを実装してみます。
Chainerのときと同様に、アイリスのデータで分類モデルを実装しました。
import datetime
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
# モデルクラス定義
class NN(torch.nn.Module):
def __init__(self, in_size, hidden_size, out_size):
# クラスの初期化
# :param in_size: 入力層のサイズ
# :param hidden_size: 隠れ層のサイズ
# :param out_size: 出力層のサイズ
super(NN, self).__init__()
self.xh = torch.nn.Linear(in_size, hidden_size)
self.hh = torch.nn.Linear(hidden_size, hidden_size)
self.hy = torch.nn.Linear(hidden_size, out_size)
def __call__(self, x):
# 順伝播を計算する関数
# :param x: 入力値
h = F.relu(self.xh(x))
h = F.relu(self.hh(h))
y = F.log_softmax(self.hy(h))
return y
# 学習
EPOCH_NUM = 100
HIDDEN_SIZE = 20
BATCH_SIZE = 20
# データ
N = 100
in_size = 4
out_size = 3
iris = load_iris()
data = pd.DataFrame(data= np.c_[iris["data"], iris["target"]], columns= iris["feature_names"] + ["target"])
data = np.array(data.values)
perm = np.random.permutation(len(data))
data = data[perm]
train, test = np.split(data, [N])
train_x, train_y, test_x, test_y = [], [], [], []
for t in train:
train_x.append(t[0:4])
train_y.append(t[4])
for t in test:
test_x.append(t[0:4])
test_y.append(t[4])
train_x = np.array(train_x, dtype="float32")
train_y = np.array(train_y, dtype="int32")
test_x = np.array(test_x, dtype="float32")
test_y = np.array(test_y, dtype="int32")
train_x = torch.from_numpy(train_x)
train_y = torch.from_numpy(train_y)
test_x = torch.from_numpy(test_x)
test_y = torch.from_numpy(test_y)
# DataLoader化
train = torch.utils.data.TensorDataset(train_x, train_y)
train_loader = torch.utils.data.DataLoader(train, batch_size=BATCH_SIZE, shuffle=True)
# モデルの定義
model = NN(in_size=in_size, hidden_size=HIDDEN_SIZE, out_size=out_size)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters())
# 学習開始
print("Train")
st = datetime.datetime.now()
for epoch in range(EPOCH_NUM):
# ミニバッチ学習
total_loss = 0
for i, data in enumerate(train_loader):
x, y = data
x, y = Variable(x), Variable(y)
optimizer.zero_grad()
y_ = model(x)
loss = criterion(y_, y)
total_loss += loss.data[0]
loss.backward()
optimizer.step()
if (epoch+1) % 10 == 0:
# accuracy
x, y = Variable(train_x), Variable(train_y)
_, y_ = torch.max(model(x).data, 1)
accuracy = sum(y.data.numpy() == y_.numpy()) / N
# test accuracy
x, y = Variable(test_x), Variable(test_y)
_, y_ = torch.max(model(x).data, 1)
test_accuracy = sum(y.data.numpy() == y_.numpy()) / len(y.data.numpy())
ed = datetime.datetime.now()
print("epoch:\t{}\ttotal loss:\t{}\taccuracy:\t{}\tvaridation accuracy\t{}\ttime:\t{}".format(epoch+1, total_loss, accuracy, test_accuracy, ed-st))
st = datetime.datetime.now()
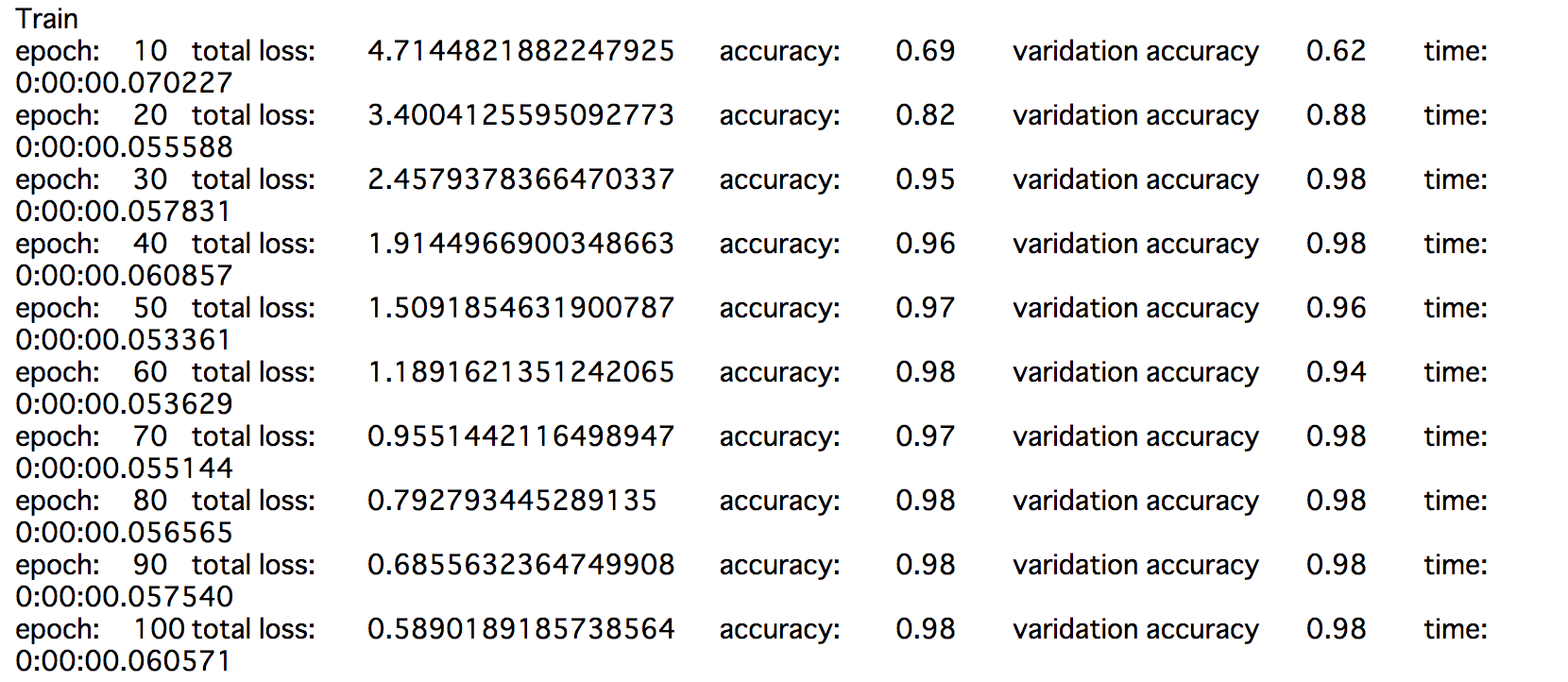
# 予測
print("Predict")
print("x\ty\tpredict")
idx = np.random.choice(len(iris.data)-N, 10)
for i in idx:
x, y = test_x[i], test_y[i]
y_ = model(x = Variable(x.view(1,len(x)))).data
_, y_ = torch.max(y_, 1)
print(x.numpy(), "\t", y, "\t", y_[0])

かなりChainerに似ていますね。
データはDataLoaderというクラスで読み込むようです。
また、numpy配列のままではなく、torchの配列にする必要があるみたいですが、ソースからわかるように、numpy配列をfrom_numpyメソッドでtorchの配列に変換できます。
PyTorchによる再帰的ニューラルネットワーク(RNN)の実装
追記(2017-10-08)
LSTMの場合はnn.LSTMを使いますが、Chainerと違い注意が必要です。
Chainerのときは、時系列の値を順に自分で入力する形でしたが、nn.LSTMでは、時系列をまるごと入力値とします。
実装は下記になります。
import datetime
import numpy as np
import matplotlib.pylab as plt
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
# RNN-LSTMで正弦波を予測するモデル
# モデルクラス定義
class LSTM(nn.Module):
def __init__(self, seq_size, hidden_size, out_size):
# クラスの初期化
# :param seq_size: 入力時系列のサイズ
# :param hidden_size: 隠れ層のサイズ
# :param out_size: 出力層のサイズ
super(LSTM, self).__init__()
self.xh = torch.nn.LSTM(seq_size, hidden_size)
self.hy = torch.nn.Linear(hidden_size, out_size)
self.hidden_size = hidden_size
def __call__(self, xs):
# 順伝播を計算する関数
# :param xs: 入力時系列
h, self.hidden = self.xh(xs, self.hidden)
y = self.hy(h)
return y
def reset(self):
# メモリの初期化
self.hidden = (Variable(torch.zeros(1, 1, self.hidden_size)), Variable(torch.zeros(1, 1, self.hidden_size))) # h, c
# 学習
EPOCH_NUM = 300
HIDDEN_SIZE = 5
BATCH_ROW_SIZE = 100 # 分割した時系列をいくつミニバッチに取り込むか
BATCH_COL_SIZE = 10 # ミニバッチで分割する時系列数
# 教師データ
train_data = np.array([np.sin(i*2*np.pi/50) for i in range(50)]*10)
# 教師データを変換
train_x, train_t = [], []
for i in range(0, len(train_data)-BATCH_COL_SIZE):
train_x.append(train_data[i:i+BATCH_COL_SIZE])
train_t.append(train_data[i+BATCH_COL_SIZE])
train_x = np.array(train_x, dtype="float32")
train_t = np.array(train_t, dtype="float32")
N = len(train_x)
model = LSTM(seq_size=BATCH_COL_SIZE, hidden_size=HIDDEN_SIZE, out_size=1)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters())
# 学習開始
print("Train")
st = datetime.datetime.now()
for epoch in range(EPOCH_NUM):
# ミニバッチ学習
x, t = [], []
# ミニバッチ学習データとして、BATCH_ROW_SIZE個用意する
for i in range(BATCH_ROW_SIZE):
index = np.random.randint(0, N) # ランダムな箇所
x.append(train_x[index]) # BATCH_COL_SIZE分の時系列を取り出す
t.append(train_t[index])
x = np.array(x, dtype="float32")
t = np.array(t, dtype="float32")
x = Variable(torch.from_numpy(x))
t = Variable(torch.from_numpy(t))
total_loss = 0
model.reset() # メモリの初期化
y = model(x)
loss = criterion(y, t)
loss.backward()
total_loss += loss.data.numpy()[0]
optimizer.step()
if (epoch+1) % 100 == 0:
ed = datetime.datetime.now()
print("epoch:\t{}\ttotal loss:\t{}\ttime:\t{}".format(epoch+1, total_loss, ed-st))
st = datetime.datetime.now()

# 予測
print("\nPredict")
predict = np.empty(0) # 予測時系列
inseq_size = 10
inseq = train_data[:inseq_size] # 予測直前までの時系列
for _ in range(N - inseq_size):
model.reset() # メモリを初期化
x = np.array([inseq], dtype="float32")
x = Variable(torch.from_numpy(x))
y = model(x)
y = y.data.numpy().reshape(1)[0]
predict = np.append(predict, y)
inseq = np.delete(inseq, 0)
inseq = np.append(inseq, y)
plt.plot(range(len(train_data)), train_data, color="red", label="t")
plt.plot(range(inseq_size+1, N+1), predict, color="blue", label="y")
plt.legend(loc="upper left")
plt.show()
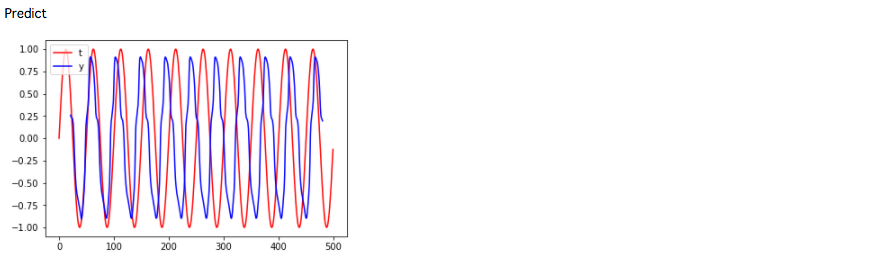
Chainerのときの実装とは、様子がだいぶ異なります。
データセットとして入力は時系列のデータの集合、出力は予測値という風に分けて使います。
また、入力する時系列のサイズに依存してしまいますので、少しばかりChainerよりも使い勝手が悪い印象です。
PyTorchによる畳み込みニューラルネットワーク(CNN)の実装
続いて畳み込みニューラルネットワークになります。
こちらも画像分類ではチュートリアルとしておなじみのMNISTの画像分類問題を実装してみました。
import datetime
import numpy as np
import matplotlib.pylab as plt
from matplotlib import cm
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
from sklearn.datasets import fetch_mldata
# 畳み込みニューラルネットワークでMNIST画像分類
# モデルクラス定義
class CNN(nn.Module):
def __init__(self):
# クラスの初期化
super(CNN, self).__init__()
# 画像を畳み込みを行うまで
self.head = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=10, kernel_size=(5, 5), stride=1, padding=0),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=10, out_channels=20, kernel_size=(5, 5), stride=1, padding=0),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
# 畳み込みで得られたベクトルを出力層に順伝播させるまで
self.tail = nn.Sequential(
nn.Linear(320, 50),
nn.ReLU(),
nn.Linear(50, 50),
nn.ReLU(),
nn.Linear(50, 10)
)
def __call__(self, x):
# 順伝播を計算する関数
# :param x: 入力値
h = self.head(x)
h = h.view(-1, 320)
h = self.tail(h)
y = F.log_softmax(h)
return y
# 学習
EPOCH_NUM = 5
BATCH_SIZE = 1000
# 教師データ
mnist = fetch_mldata('MNIST original', data_home='.')
mnist.data = mnist.data.astype(np.float32) # 画像データ 784*70000 [[0-255, 0-255, ...], [0-255, 0-255, ...], ... ]
mnist.data /= 255 # 0-1に正規化する
mnist.target = mnist.target.astype(np.int32) # ラベルデータ70000
# 教師データを変換
N = 60000
train_x, test_x = np.split(mnist.data, [N]) # 教師データ
train_t, test_t = np.split(mnist.target, [N]) # テスト用のデータ
train_x = train_x.reshape((len(train_x), IN_CHANNELS, 28, 28)) # (N, channel, height, width)
test_x = test_x.reshape((len(test_x), IN_CHANNELS, 28, 28))
# DataLoader化
train = torch.utils.data.TensorDataset(torch.from_numpy(train_x), torch.from_numpy(train_t))
train_loader = torch.utils.data.DataLoader(train, batch_size=BATCH_SIZE, shuffle=True)
test = torch.utils.data.TensorDataset(torch.from_numpy(test_x), torch.from_numpy(test_t))
test_loader = torch.utils.data.DataLoader(test, batch_size=BATCH_SIZE, shuffle=True)
# モデルの定義
model = CNN()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters())
# 学習開始
print("Train")
st = datetime.datetime.now()
for epoch in range(EPOCH_NUM):
# ミニバッチ学習
total_loss = 0
for i, data in enumerate(train_loader):
x, t = data
x, t = Variable(x), Variable(t)
optimizer.zero_grad()
y = model(x)
loss = criterion(y, t)
total_loss += loss.data[0]
loss.backward()
optimizer.step()
if (epoch+1) % 1 == 0:
ed = datetime.datetime.now()
print("epoch:\t{}\ttotal loss:\t{}\ttime:\t{}".format(epoch+1, total_loss, ed-st))
st = datetime.datetime.now()

# 予測
print("\nPredict")
def predict(model, x):
x_ = np.array([x], dtype="float32")
x_ = torch.from_numpy(x_)
x_ = Variable(x_)
y = model(x_)
_, y = torch.max(y.data, 1)
plt.figure(figsize=(1, 1))
plt.imshow(x[0], cmap=cm.gray_r)
plt.show()
print("y:\t{}\n".format(y[0]))
idx = np.random.choice((70000-N), 10)
for i in idx:
predict(model, test_x[i])

まとめ
以上、PyTorchでニューラルネットワークと畳み込みニューラルネットワークを実装してみました。
Chianerと一緒とまではいきませんが、やはり基本的にChainerを使っている身からすると、学習コストは低い方なのかなと思います。
あと、個人的に使っていて思ったのは、Chainerよりも学習速度が早く感じました。
上記のときと実行時間を比べてみても、やっぱりだいぶ早いのではないかと思います。
基本的に深層学習はGPUで動作させるものなので、CPUだけの結果だと何とも言えませんけど...。
追記(2017-10-24)
TensorFlowも実装してみました。
コメント
CNNの実装時の教師データ変換にて、IN_CHANNELSとあるのですがこれはどこで定義しているのでしょうか?
後、現在機械学習の勉強しているのですが、このような実装を出来るようになるためにどういった勉強をなされたのでしょうか?
コメントありがとうございます。
`IN_CHANNELS` はコードから漏れていますね…。失礼いたしました。
データがMNISTであることや、モデルの実装を見ても分かるように、ここでは `IN_CHANNELS = 1`です。
勉強方法は、私の場合は、ひたすら実装を繰り返しています。
参考になるコードを探して、まずは再現してみて、次はデータセットを変えて同じことをやってみたり、モデルや学習を少し変えてみたり、ということを繰り返して、
コードで何をやっているのか理解するように努めています。