一応、前回の続編的な感じになります。
前回は自己符号化器で画像の画素値を次元圧縮し、得られた特徴量を使って類似度計算を行ってみました。
今回は、モデルを一から学習するのではなく、転移学習で得られた特徴量を使って類似度計算してみます。
深層学習のライブラリは、実装が楽だったため、Chainerを使いました。
転移学習とファインチューニング
転移学習、ファインチューニング共に、既存の学習済みモデルを使う方法のことを指します。
ただし、厳密には若干意味が異なり、それぞれ
- 転移学習: 学習済みモデルの重みデータを変更せずに、特徴量抽出に利用すること
- ファインチューニング: 学習済みモデルの重みデータを一部変更・再学習した後に、特徴量抽出に利用すること
といった意味のようです。
参考: https://www.quora.com/What-is-the-difference-between-transfer-learning-and-fine-tuning
今回のように特徴量抽出のみに利用する場合は、転移学習となります。
対して、ある分類問題の精度向上のために学習済みモデルの一部重みを利用して再学習させる場合はファインチューニングと呼んで、使い分けるようです。
転移学習と類似度の計算
今回はVGG16の学習済みCaffeモデルを利用します。
VGG16は2014年のILSVRC(ImageNet Large Scale Visual Recognition Challenge)で準優勝の畳み込みニューラルネットワークモデルです。
下記のようなネットワーク構造をしています。
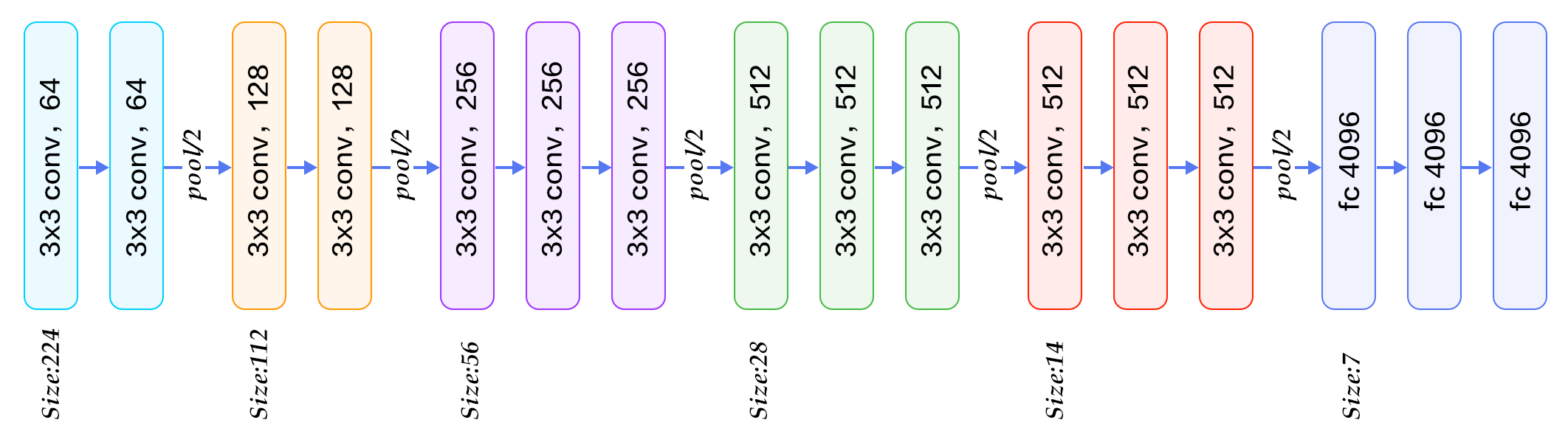
これの学習済みモデルを読み込んで、転移学習をしてみます。
ソースコードは全て下記にあげました。
移設&少し更新しました。
データセットは前回同様、下記のKaggle Datasetの花の画像を利用します、
Flower Color Images: https://www.kaggle.com/olgabelitskaya/flower-color-images
まずは学習済みモデルの重みファイルをダウンロードします。
wget http://www.robots.ox.ac.uk/~vgg/software/very_deep/caffe/VGG_ILSVRC_16_layers.caffemodel
これでVGG16の学習済みCaffeモデルを取得できます。
このままでは、Caffeeで学習した重みファイルのままなので、Chainerでは読み込めませんが、Chainerには、Caffeeモデルで学習したパラメータをChainerで読み込める形式に変換するメソッドがあります。
import chainer.links as L
caffemodel = './VGG_ILSVRC_16_layers.caffemodel'
chainermodel = './VGG_ILSVRC_16_layers.npz'
L.VGG16Layers.convert_caffemodel_to_npz(caffemodel, chainermodel)
これで、Chainerで読み込める形式のVGG16の学習済みモデル VGG_ILSVRC_16_layers.npz が出力されます。
次に、ChainerでVGG16のネットワークを作成します。
このネットワーク自体もChainerでは、 L.VGG16Layers メソッド一発で読み込めるようになっています。
これの引数に重みファイルを指定してあげると、重みを反映したモデルインスタンスを作成してくれます。
vgg = L.VGG16Layers(chainermodel)
VGG16では、画像を読み込む際に、下記のような独自の変換処理を行います。
- (batch_size, chennels, height, width) = (None, 3, 224, 224) に合わせる
- カラーのチャンネルの順番は (BGR) にする
- 各画素値から平均値 (103.939, 116.779, 123.68) を引く
Chainerではこの処理も、VGG16インスタンスのメソッドである extract で画像データだけ渡してあげると、自動的に上記の変換も行ってくれるようになっています。
例えば、画像を入力して、クラス分類前の全結合層 fc7 の出力値(特徴量)を出力させるには、下記のように書きます。
from PIL import Image
img = Image.open(path)
feature = vgg.extract([img], layers=['fc7'])['fc7']
お手軽感がすごいです笑
上記を使って、花の画像データセットを入力して、特徴量を取得していきます。
images_path = './flower_images/*.png'
paths, features = [], []
for path in tqdm(glob.glob(images_path)):
paths.append(path)
img = Image.open(path)
if img.mode != 'RGB':
img = img.convert('RGB')
feature = vgg.extract([img], layers=['fc7'])['fc7']
feature = feature.data.reshape(-1)
features.append(feature)
features = np.array(features)
花の画像が210枚で、特徴量の次元数が4096なので、features.shape = (210, 4096) となります。
そして、下記のようにコサイン類似度のマトリクスに計算してあげます。
def cos_sim_matrix(matrix):
d = matrix @ matrix.T
norm = (matrix * matrix).sum(axis=1, keepdims=True) ** .5
return d / norm / norm.T
cos_sims = cos_sim_matrix(features)
前回同様にいくつかサンプリングしてみて、類似度が高い順に画像を表示してみます。
samples = np.random.randint(0, len(paths), 10)
for i in samples:
sim_idxs = np.argsort(cos_sims[i])[::-1]
sim_idxs = np.delete(sim_idxs, np.where(sim_idxs==i))
sim_num = 3
sim_idxs = sim_idxs[:sim_num]
fig, axs = plt.subplots(ncols=sim_num+1, figsize=(15, sim_num))
img = Image.open(paths[i])
axs[0].imshow(img)
axs[0].set_title('target')
axs[0].axis('off')
for j in range(sim_num):
img = Image.open(paths[sim_idxs[j]])
axs[j+1].imshow(img)
axs[j+1].set_title(cos_sims[i, sim_idxs[j]])
axs[j+1].axis('off')
plt.show()

転移学習だけでも、花の間の特徴を捉えているようです。
t-SNEによる特徴量の可視化
上記の特徴量がどれだけ花の特徴を捉えてくれているのか、t-SNEで次元圧縮をして、2次元プロットしてみます。
from sklearn.manifold import TSNE
tsne_model = TSNE(n_components=2).fit_transform(features)
canvas_size = (1000, 1000)
img_size = (50, 50)
canvas = Image.new('RGB', canvas_size)
val_max = np.array(tsne_model).max()
val_min = np.array(tsne_model).min()
for i, path in enumerate(paths):
pos_x = int(tsne_model[i][0]*(canvas_size[0]/img_size[0])/(val_max-val_min))*img_size[0]
pos_y = int(tsne_model[i][1]*(canvas_size[1]/img_size[1])/(val_max-val_min))*img_size[1]
pos = (int(pos_x+canvas_size[0]/2), int(pos_y+canvas_size[1]/2))
target_img = Image.open(path)
target_img = target_img.resize(img_size)
canvas.paste(target_img, pos)
target_img.close()
plt.figure(figsize=(15,15))
plt.imshow(np.array(canvas))
plt.axis('off')
plt.show()

はっきりと固まりが分かれてくれているわけではなさそうですが、色や形などの特徴によって固まりやすいように分布されていることが確認できました。
ところどころ、こっちに行って欲しいとか、あっちに行って欲しいといった画像が見受けられますので、ここからさらにファインチューニングをしてみて、上記可視化がどのように変化するのか、試してみたいところです。
追記(2017-12-22)
ファインチューニングも試してみました。
追記(2018-04-04)
他の学習済みモデルも含め、転移学習・ファインチューニングの方法をまとめてみました。
コメント