先月、第25回が放送されたばかりのIPPONグランプリですが、最近こんな動画みっけました。
(敬称略)
さすがの最多出場回数を誇るバカリズムの無双感。
累計本数となれば、たくさん出場している人ほど上位に食い込むのは当たり前ですよね。
動画の概要に書いてある通り、平均IPPON取得回数の方が、よりIPPON力ランキングという視点では近いのかなと思います。
だけど、それでも予選でサドンデスマッチをやった人だったり、決勝戦にいった人は、その分だけ回答権が得られている分、平均でも優位な形になりますね。
また、お題は当然毎回変わる上に、最近は画像や動画のお題が出たりと出題形式もたびたび変わっていたりして、IPPONを出しやすい回・出しにくい回というのもあるのかなと、客観的に見て思ったりしています。
なので、ちょっとそういった要素も考慮した上で、本当にIPPON力が高い芸人は誰なのかを、今回ベイズモデリングで分析してみようと思います。
全ソースは以下の通り
GitHub: 整理中
kaggle notebook: https://www.kaggle.com/itoeiji/ippon-gp-analysis
データの取得・加工
過去のIPPONの記録は、wikipediaに面白いくらい綺麗にまとまっていました。
- https://ja.wikipedia.org/wiki/IPPON%E3%82%B0%E3%83%A9%E3%83%B3%E3%83%97%E3%83%AA
綺麗に構造化されているわけではありませんが、過去の出場者、IPPON数、予選の結果、サドンデスマッチを行ったかどうか、決勝戦の結果などなど、細かい情報の把握が可能です。
というわけで、これを手で構造化します←
データサイエンティストは地味にこういった作業をやることが一番多い気がします←
誤解を招いたら大変なので、本当はやりたくないです←
ちまちまエクセルに張り付けて、こねこね弄って、小一時間ほどで以下のような形に整理できました。
`ippon_gp_data_asof_20210531.csv`
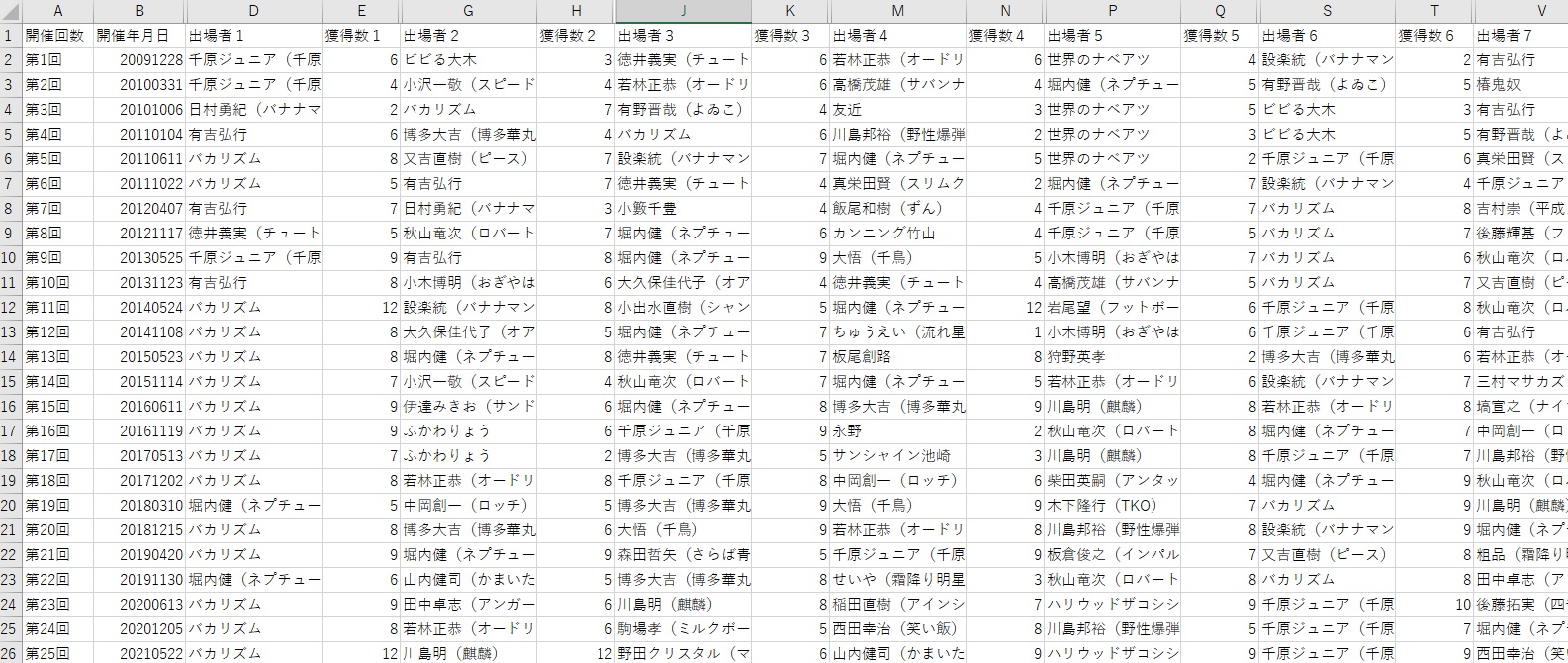
ここで、分析するIPPON数は予選の結果のみのIPPON数とします。
加えて、サドンデスマッチによる回答権の数の偏りを防ぐため、サドンデスマッチで取得したIPPONはカウントから除外しています。
また、中には参加回で芸名の表記が異なるパターンもありましたので、なるべく一つの芸名に名寄せしています。(例:世界のナベアツ、桂三度は、世界のナベアツに統一)
あまり詳しくないんで、ミスってたらゴメンなさい。
こうして、できる限り全ての芸人が同じ回答権を得られている状態でのIPPON数を分析します。(まあ、実際見ていると早押し力とかもありそうですが)
基礎的な分析をしてみる
いきなりモデリングに入る前に、とりあえず出場回数と平均IPPON数をプロットしてみようと思います。
以下はライブラリのインポート。
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pylab as plt
import japanize_matplotlib
import seaborn as sns
import pystan
import arviz
で、前述で整理したファイルを読み込み。
df_ippon = pd.read_csv('/kaggle/input/ippon-gp-data/ippon_gp_data_asof_20210531.csv')
ちょっと色々と細かくデータ加工しそうでデータフレームのままだと扱いづらいので、以下のような辞書形式に。
dic_ippon = {}
for i, row in df_ippon.iterrows():
dic_ippon[i] = {
row['出場者1']: row['獲得数1'],
row['出場者2']: row['獲得数2'],
row['出場者3']: row['獲得数3'],
row['出場者4']: row['獲得数4'],
row['出場者5']: row['獲得数5'],
row['出場者6']: row['獲得数6'],
row['出場者7']: row['獲得数7'],
row['出場者8']: row['獲得数8'],
row['出場者9']: row['獲得数9'],
row['出場者10']: row['獲得数10'],
}
dic_ippon
{0: {'千原ジュニア(千原兄弟)': 6,
'ビビる大木': 3,
'徳井義実(チュートリアル)': 6,
'若林正恭(オードリー)': 6,
'世界のナベアツ': 4,
'設楽統(バナナマン)': 2,
'有吉弘行': 5,
'箕輪はるか(ハリセンボン)': 3,
'バカリズム': 7,
'ケンドーコバヤシ': 5},
1: {'千原ジュニア(千原兄弟)': 4,
'小沢一敬(スピードワゴン)': 4,
'若林正恭(オードリー)': 6,
'高橋茂雄(サバンナ)': 4,
'堀内健(ネプチューン)': 5,
'有野晋哉(よゐこ)': 5,
'椿鬼奴': 6,
'設楽統(バナナマン)': 7,
'川島邦裕(野性爆弾)': 5,
'世界のナベアツ': 7},
2: {'日村勇紀(バナナマン)': 2,
'バカリズム': 7,
'有野晋哉(よゐこ)': 4,
'友近': 3,
'世界のナベアツ': 5,
'ビビる大木': 3,
'有吉弘行': 5,
'塚地武雅(ドランクドラゴン)': 5,
'西田幸治(笑い飯)': 4,
'ケンドーコバヤシ': 4},
3: {'有吉弘行': 6,
'博多大吉(博多華丸・大吉)': 4,
'バカリズム': 6,
'川島邦裕(野性爆弾)': 2,
'世界のナベアツ': 3,
'ビビる大木': 5,
'有野晋哉(よゐこ)': 3,
'椿鬼奴': 3,
'小木博明(おぎやはぎ)': 6,
'高橋茂雄(サバンナ)': 6},
...
一旦、各芸人の出場回数および平均IPPON数をプロットしてみます。
player_scores = {}
for key, values in dic_ippon.items():
for player_name, score in values.items():
if player_name not in player_scores:
player_scores[player_name] = [score]
else:
player_scores[player_name].append(score)
player_list = []
mean_score_list = []
participating_num_list = []
for player_name, scores in player_scores.items():
player_list.append(player_name)
mean_score_list.append(np.mean(scores))
participating_num_list.append(len(scores))
df_tmp = pd.DataFrame({'player': player_list, 'mean_score': mean_score_list, 'participating_num': participating_num_list})
df_tmp = df_tmp.sort_values(by='mean_score', ascending=False)
plt.rcParams["font.size"] = 15
fig, ax1 = plt.subplots(figsize=(25, 7))
ax2 = ax1.twinx()
sns.barplot(x=df_tmp['player'], y=df_tmp['mean_score'], color='skyblue', ax=ax1)
sns.scatterplot(x=df_tmp['player'], y=df_tmp['participating_num'], color='black', s=200, ax=ax2)
fig.autofmt_xdate(rotation=90)
plt.show()
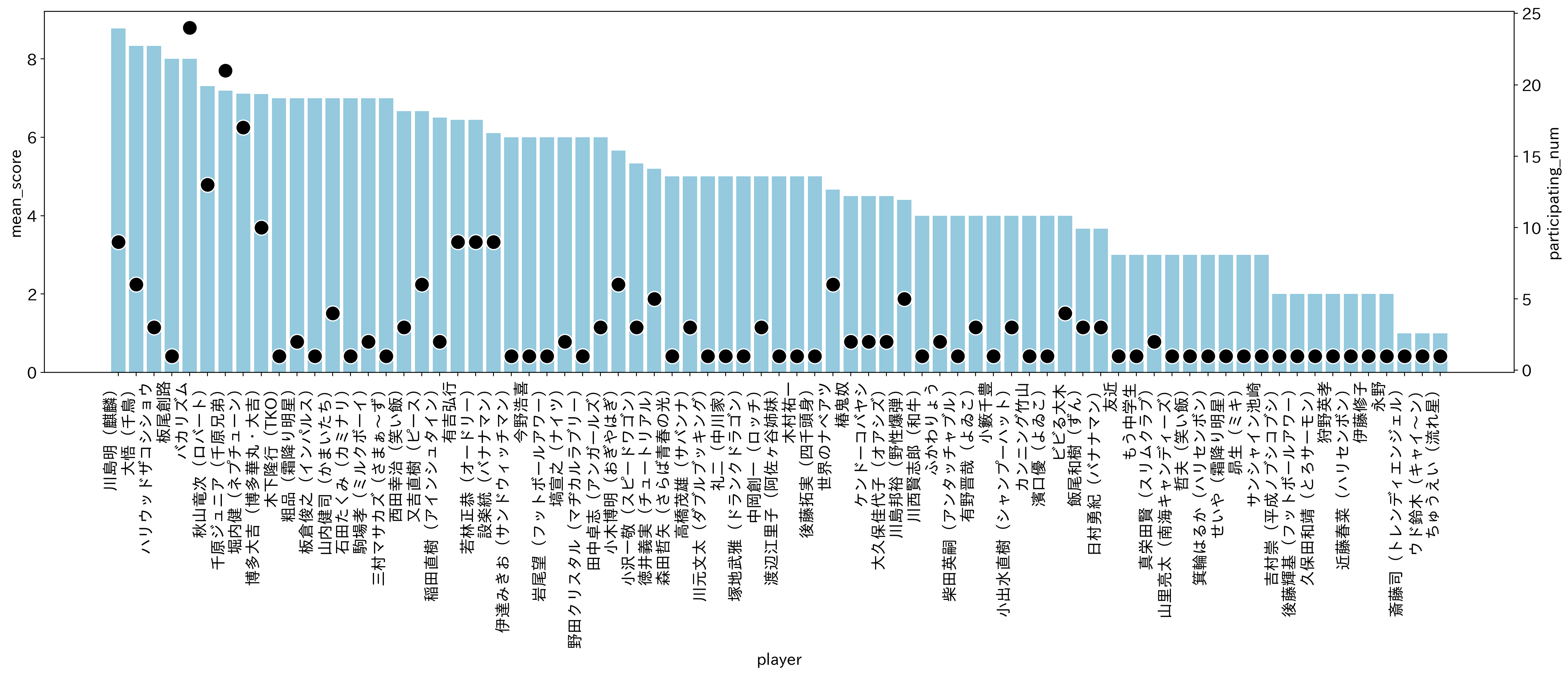
青色の棒グラフおよび左y軸の目盛りが平均IPPON数、黒丸および右y軸の目盛りが出場回数として、平均IPPON数で降順してプロットしてみました。
こうしてみると、確かにIPPONグランプリ常連で出場回数が多いバカリズムや千原ジュニアは、強い方に位置しています。
そのさらに左側の強い方の塊に、出場回数こそまだあまり回数を重ねていないものの、その出場回においてIPPONが多かった芸人が位置しています。
だけど、この塊は個人的な感覚ですが、割と最近の回から出始めた芸人が多い気がします。
そうしてみると、IPPONグランプリ常連組のすぐ右側に位置している芸人たちも、割と最近の回の芸人のような気もしていて、昔に比べると最近の方がIPPONが出しやすい形式になっていそうな雰囲気があります。
(まぁ、その方が番組は盛り上がりますし、番組側は番組側で改善していっているということなのかもしれません)
というわけで、ちょっとそんな要素を取り入れつつベイズモデリングで分析してみたいと思います。
ベイズモデリングで分析してみる
今回は割とシンプルなモデルにします。
![\[{\forall} player, {\forall} t {\in} \{1,2,\lodts,25\}, \hspace{2em} score_{player,t} {\sim} Poisson(\mu_{player} + \mu_t)\]](https://ie110704.net/wp-content/ql-cache/quicklatex.com-c62ff01230dec4e2f11c87153b2bb33b_l3.png "Rendered by QuickLaTeX.com")
強いて式を書くならば、本当にこれだけ。
各芸人の平均IPPON数  (=IPPON力)とそのグランプリで元々取れるであろうとされる平均IPPON数
(=IPPON力)とそのグランプリで元々取れるであろうとされる平均IPPON数  (=IPPON取得しやすさ)のそれぞれの事後分布を求めます。
(=IPPON取得しやすさ)のそれぞれの事後分布を求めます。
Stanのモデルに入力するためのデータ配列を、以下のように準備します。
# Need to prepare participating_players and scores
# Prepare participating_players
# First, create a dictionary that player_name to player_id
# and, a dictionary that player_id to player_name
player_name_player_id = {}
player_id_player_name = {}
for key, values in dic_ippon.items():
for player_name, score in values.items():
if player_name not in player_name_player_id:
player_name_player_id[player_name] = len(player_name_player_id)
player_id_player_name = {v: k for k, v in player_name_player_id.items()}
# Second, create participating_players
participating_players = []
for key, values in dic_ippon.items():
players = []
for player_name in values:
players.append(player_name_player_id[player_name])
participating_players.append(players)
# Check that all of matches, participating players num is 10
for i, pp in enumerate(participating_players):
if len(pp) != 10:
print(i, 'match, player num was NOT 10. player num = ', len(pp))
# Next prepare scores
scores = []
# prepare player's score rows
for _ in range(len(player_name_player_id)):
scores.append([])
# adding a score
for key, value in dic_ippon.items():
for player_id, player_name in player_id_player_name.items():
if player_name in value:
scores[player_id].append(value[player_name])
else:
scores[player_id].append(-1)
改めて、この状態で各グランプリでの各芸人の実績を確認してみます。
# Visualize scores
fig, ax1 = plt.subplots(figsize=(20, 30))
yticklabels = list(player_name_player_id.keys())
sns.heatmap(scores, ax=ax1, cmap='binary', annot=True, annot_kws={'color': 'white'}, cbar=True, cbar_kws={'shrink': .3}, linewidths=.1, yticklabels=yticklabels)
plt.show()

縦軸に芸人、横軸に第何回かが並ぶ形で、芸人が該当グランプリに参加していれば、そのマスに取得したIPPON数が可視化されています。
バカリズムって第2回以外、全て出場しているんですね。
さて、前述モデルと、学習を以下のような感じで行います。
N = len(player_name_player_id)
T = len(dic_ippon)
data = {
'N': N,
'T': T,
'participating_players': participating_players,
'scores': scores,
}
model = """
data {
int N;
int T;
int participating_players[T, 10];
int scores[N, T];
}
parameters {
real mu_player[N];
real mu_gp[T];
}
model {
for (t in 1:T) {
for (i in 1:10) {
scores[participating_players[t, i] + 1, t] ~ poisson(mu_player[participating_players[t, i] + 1] + mu_gp[t]);
}
}
}
"""
fit = pystan.stan(
model_code=model,
data=data,
iter=1000,
chains=4,
)
la = fit.extract()
結果の可視化についてですが、今回は職場の同僚に以下のライブラリを教えてもらいましたので、使ってみます。
ArviZ: https://arviz-devs.github.io/arviz/
概要としては、以下のように書いてあります。
ArviZ is a Python package for exploratory analysis of Bayesian models. Includes functions for posterior analysis, data storage, sample diagnostics, model checking, and comparison.
ベイジアンモデルの解析に使えるPythonライブラリのようで、事後分布の確認だったり、モデルの確認だったり、比較だったりと、ベイジアンモデルを構築した時に色々とありがちな解析を簡単にやってくれるライブラリのようです。
サポートしているベイジアンライブラリもPyMC3、PyStan、CmdStanPy、Pyro、NumPyro、emcee、TensorFlow Probability、Edward2と抜け目なく対応されているみたいです。
っていうか、こんなにあるんですね。
結構知らないライブラリもありますね。
例えば、各グランプリでのIPPON取得しやすさの分布は、以下のようにして確認できました。
fig, ax1 = plt.subplots(figsize=(10, 15))
arviz.plot_forest(fit, var_names=['mu_gp'], ax=ax1)
ax1.set_yticklabels([f'第{t}回' for t in range(T, 0, -1)])
plt.show()
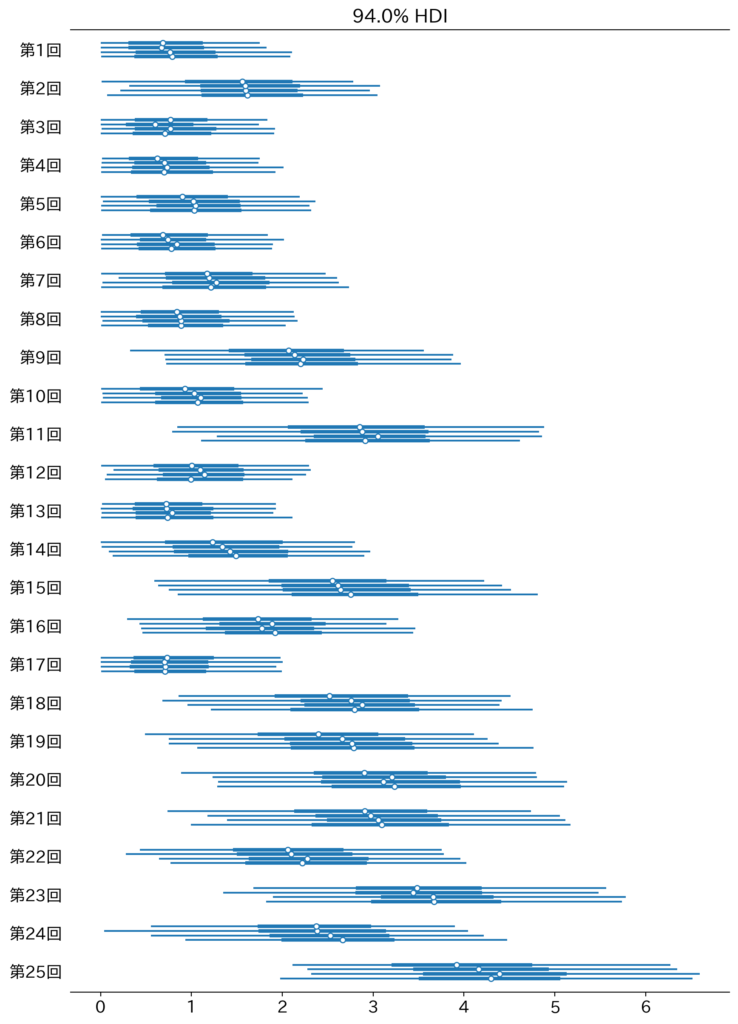
トレースごとにプロットもされているみたいで分かりやすいですね。
HDIは、Highest Density Intervalですかね。
ちょっとよく分かっていないのですが、定義的にはCredible Interval(信用区間)と同じ認識なんですが、この辺り、もし詳しい人がいれば教えて下さい。
結果を見る限り、やはり後半になればなるほど、その時のIPPONの取りやすさが上がっていっているような気がします。
まあこれ、読み通り、番組側がお題のバリエーションが増やして取りやすくして番組自体が盛り上がるように調整してきているのか、あるいは、全体的に芸人のレベルが上がっているのかという視点もありそうな気はしますが。
見る限り第18回以降から全体的に上がっている気がしますが、このタイミングで何かしら大枠的なルールが変更されたみたいなソースは見つかりませんでした。
変則的な出題として画像でルーレットが最初に思いつきますが、こちらは第10回以降から採用されているようです。
ですが、どういうわけか分かりませんが、Wikipediaのルール説明では偶然にも「第18回以降のルール」と明記の上説明されています。
この辺り、もし何か気づいた人がいれば教えて下さい。
次に、芸人のIPPON取得数(IPPON力)の事後分布を可視化してみます。
fig, ax1 = plt.subplots(figsize=(10, 40))
arviz.plot_forest(fit, var_names=['mu_player'], ax=ax1)
ax1.set_yticklabels([pn for pn in reversed(list(player_name_player_id.keys()))], fontsize=24)
ax1.set_xticklabels(ax1.get_xticklabels(), fontsize=18)
plt.show()
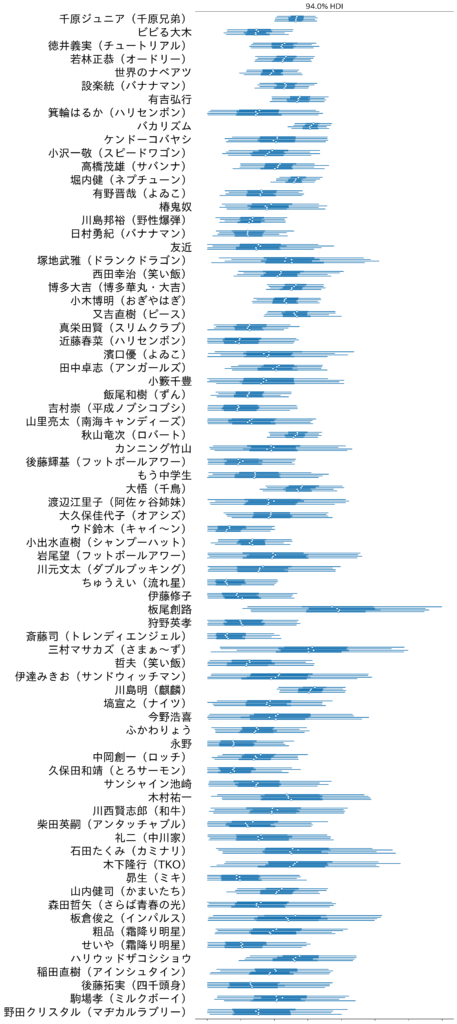
うーん、これはちょっと見づらいかな?
できる限り一画面に収まって一視野に可視化されると分かりやすいのですが...。
縦軸・横軸を入れ替えて横に並べてみたらどうかなと思って、horizontalとかverticalとか、それっぽいパラメータがあるか調べてみましたけども、どうやらarvizにはそのようなパラメータは無さそうでした。
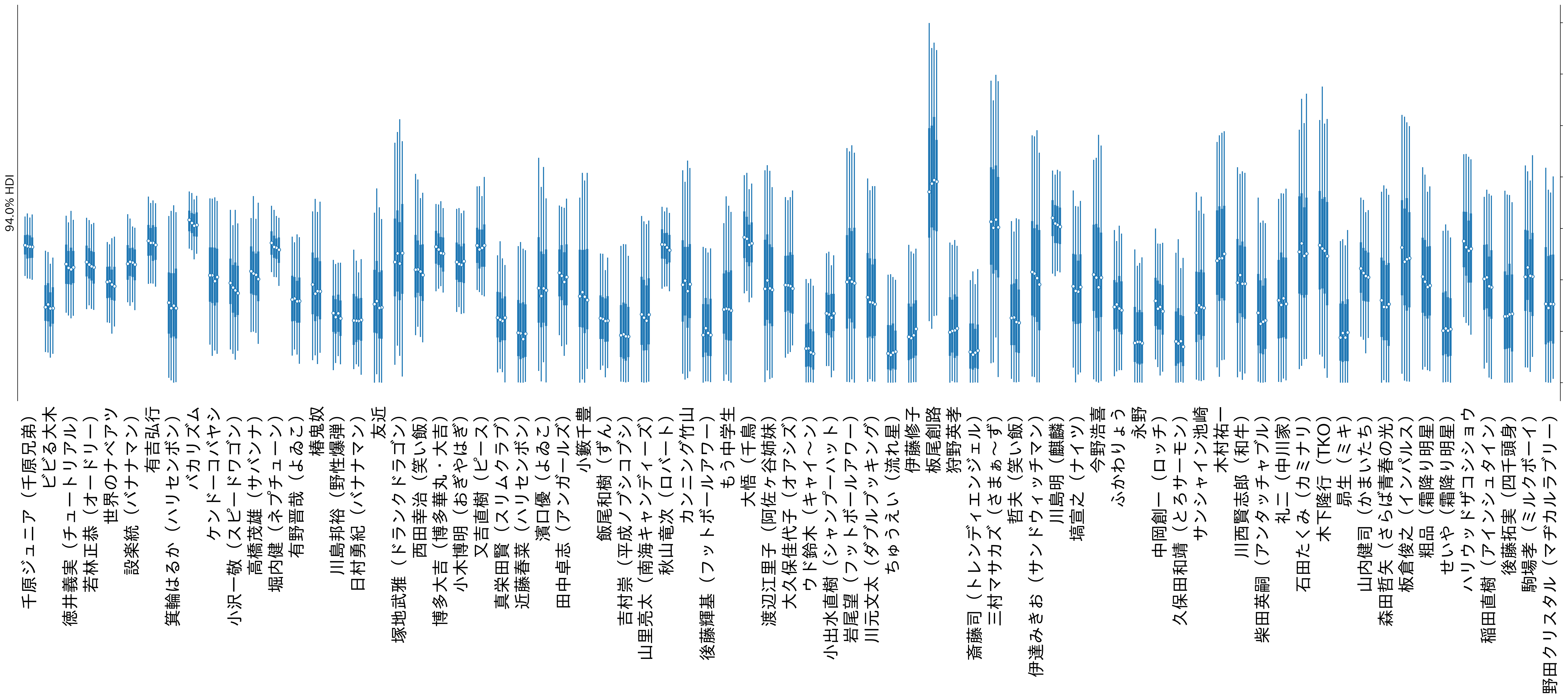
とりあえず上記のグラフの画像ファイルをそのまま横に回してみました。
多少はマシかな...?
さて、区間幅が大きいけども、中央値が一番大きく出ているのが、板尾創路氏!
前述、平均IPPON取得数の集計では4位になっていました。
意外に思いましたが、前述の各グランプリ各芸人実績の可視化を確認してみると、どうやら板尾創路が出ている第13回においては、先のIPPON取得しやすさは決して高くなく、実際その回に出ている他の芸人のIPPON数を見ると、結構少なかったりしています。
そんな、周りの芸人が苦戦する中、IPPONを8本とっているということは、実はIPPON力が高いのでは、という分析結果となりました。
しかし、実際はその回では堀内健が同予選で同じく8本を取得していて、サドンデスで負けているため、決勝進出できていません。(サドンデスは出場者の回答権数を同じにするため、集計上除外しています)
もしかしたら回を重ねていっていたら落ち着いていくのかもしれません。
分析結果を中央値でランキングして上位20位まで出した結果が以下になります。
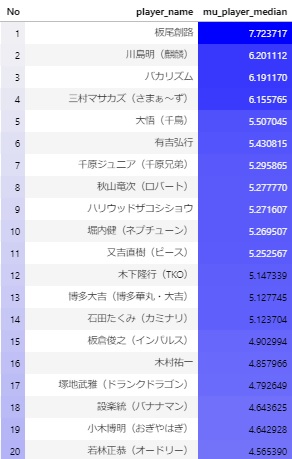
確かにバカリズムは安定して強いですねw
これで上位10人で開催してみたら一体どんな感じになるんでしょうか。ちょっと気になります。
最後に
以上、今回は過去のIPPONグランプリの成績を元に、各芸人の面白さの分析をしてみました。
最後にですが、ここではちょっとだけ真面目にIPPONグランプリでの強さを分析してみただけの記事になりますので、今回の結果がそのまま芸人の面白さに繋がるわけではないと思っています。
こういったお題に対する回答で笑わせる能力が高い人もいれば、漫才のようにある意味作品を作って笑わせる能力が高い人、フリートークで面白い人、話術だけでなく体や動きを駆使して面白い人とか、色々あると思います。
あと、不思議なんですが、M-1グランプリのwikipediaも凄く詳細に過去の記録が取れています。
M-1グランプリ wikipedia: https://ja.wikipedia.org/wiki/M-1%E3%82%B0%E3%83%A9%E3%83%B3%E3%83%97%E3%83%AA
この辺りのお笑いものの情報は、wikipediaにしっかりと記録されやすい傾向でもあるんでしょうかw
もし需要があれば、こちらも何かしら分析ネタをやってみても面白いかもしれないなと思いました。
コメント