まただいぶ更新期間が空いてしまいました。
今回は、表題の通り、深層学習でのBi-LSTMなどの系列学習において、バッチごとに系列長を調整できるようにしてみます。
例えば、Kaggleのカーネルコンペなどで、自然言語の分類をLSTMなどで学習させる場合、バッチごとに系列長を調整する方が、学習精度・実行時間短縮に効果があるようです。
実際にどのように書いて、どのくらい速度に違いが出るか、Kerasで比較してみようと思います。
今はTransformerだろとかBERTだろとか言われそうな気もしますが、そうでもないよ的な論文もちらほら出ていて、色々と決着がついてなさそうですし、一旦無視していきます。
データは、以下のKaggleのデータセットを使います。
- https://www.kaggle.com/mousehead/songlyrics
Kaggleのカーネルで実験しましたので、コードはカーネルでも公開しています。
タスクと普通の学習コード
まずは解くタスクと、普通に学習させる場合のコードで学習させてみます。
データセットは、アーティスト(歌手)と曲名と歌詞の文章データセットになっています。
今回はこれを使って、歌詞からアーティストを予測できるか学習させてみます。
といっても、本来の目的は、バッチごとの系列長調整の比較ですので、精度の追求はしません。
早速コードを書いていきます。
定数パラメータは以下のようにします。
DATA_FILE = '../input/songlyrics/songdata.csv'
EMBEDDING_FILE = '../input/glove840b300dtxt/glove.840B.300d.txt'
TEXT_COLUMNS = 'text'
TARGET_COLUMNS = 'artist'
EPOCHS = 10
BATCH_SIZE = 256
LSTM_UNITS = 128
DENSE_UNITS = 4 * LSTM_UNITS
MAX_LEN = 1000
CHARS_TO_REMOVE = '!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n“”’\'∞θ÷α•à−β∅³π‘₹´°£€\×™√²—'
データセットを読み込んで、以下のように加工します。
df = pd.read_csv(DATA_FILE, usecols=[TARGET_COLUMNS, TEXT_COLUMNS], dtype=str)
df = pd.merge(df, df.groupby(TARGET_COLUMNS).size().to_frame(name='size') > 180, how='left', on=TARGET_COLUMNS)
df = df[df['size']][[TARGET_COLUMNS, TEXT_COLUMNS]]
print('data size:', df.shape)
n_class = df[TARGET_COLUMNS].unique().shape[0]
print('n_class: ', n_class)
df[TARGET_COLUMNS] = preprocessing.LabelEncoder().fit_transform(df[TARGET_COLUMNS])
df = df.sample(frac=1) # shuffle
X = df[TEXT_COLUMNS].astype(str)
y = df[TARGET_COLUMNS].values
tokenizer = text.Tokenizer(filters=CHARS_TO_REMOVE)
tokenizer.fit_on_texts(X)
X = tokenizer.texts_to_sequences(X)
X = sequence.pad_sequences(X, maxlen=MAX_LEN)
y = preprocessing.LabelBinarizer(neg_label=0, pos_label=1).fit_transform(y)
X_train, X_valid, y_train, y_valid = model_selection.train_test_split(X, y, test_size=0.3)
print(X_train.shape, y_train.shape, X_valid.shape, y_valid.shape)
embedding_matrix = build_matrix(tokenizer.word_index, EMBEDDING_FILE)

全データには、曲が一つしかないアーティストなどもたくさん入ってきて、クラス数が多すぎになってしまいますので、上記のように180曲以上出している有名アーティスト20クラスで分類してみます。
ちなみに私は音楽詳しくないので、そんなに曲を出しているアーティスト名を確認してみてもさっぱりだったりします←
しかし単純に、およそ200曲分の歌詞で20人分のアーティストをちゃんと分類を学習できるのか、これもこれで興味があります。
単語埋め込みベクトルの取得部分 build_matrix は以下のようにGloveの単語埋め込みベクトルを使うようにしました。
def get_coefs(word, *arr):
return word, np.asarray(arr, dtype='float32')
def load_embeddings(path):
with open(path) as f:
return dict(get_coefs(*line.strip().split(' ')) for line in f)
def build_matrix(word_index, path):
embedding_index = load_embeddings(path)
embedding_matrix = np.zeros((len(word_index) + 1, 300))
for word, i in word_index.items():
embedding_vector = embedding_index.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
continue
embedding_vector = embedding_index.get(word.lower())
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
continue
embedding_vector = embedding_index.get(word.upper())
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
continue
embedding_vector = embedding_index.get(word.title())
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
continue
embedding_matrix[i] = np.random.normal(loc=0, scale=1, size=(1,300))
return embedding_matrix
できる限り埋め込みベクトルにある単語になるよう合わせて、それでもなければランダムなベクトルを利用するといったスタイルです。
さて、モデルを以下のように適当に組んでみます。
Bi-LSTMで文章系列の隠れ層を学習して、分類するモデルを作りました。
def build_model(embedding_matrix, out_size):
words = Input(shape=(None,))
x = Embedding(*embedding_matrix.shape, weights=[embedding_matrix], trainable=False)(words)
x = SpatialDropout1D(0.2)(x)
x = Bidirectional(CuDNNLSTM(LSTM_UNITS, return_sequences=True))(x)
hidden = GlobalMaxPooling1D()(x)
hidden = Dense(DENSE_UNITS, activation='relu')(hidden)
hidden = Dropout(0.2)(hidden)
hidden = BatchNormalization()(hidden)
result = Dense(out_size, activation='sigmoid')(hidden)
model = Model(inputs=words, outputs=result)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
単純なKerasのやり方でEPOCH分学習させてみます。
model = build_model(embedding_matrix, n_class)
for global_epoch in range(EPOCHS):
model.fit(
X_train, y_train, batch_size=BATCH_SIZE, epochs=1, verbose=2, validation_data=(X_valid, y_valid),
callbacks=[LearningRateScheduler(lambda _: 1e-3 * (0.9 ** global_epoch))]
)
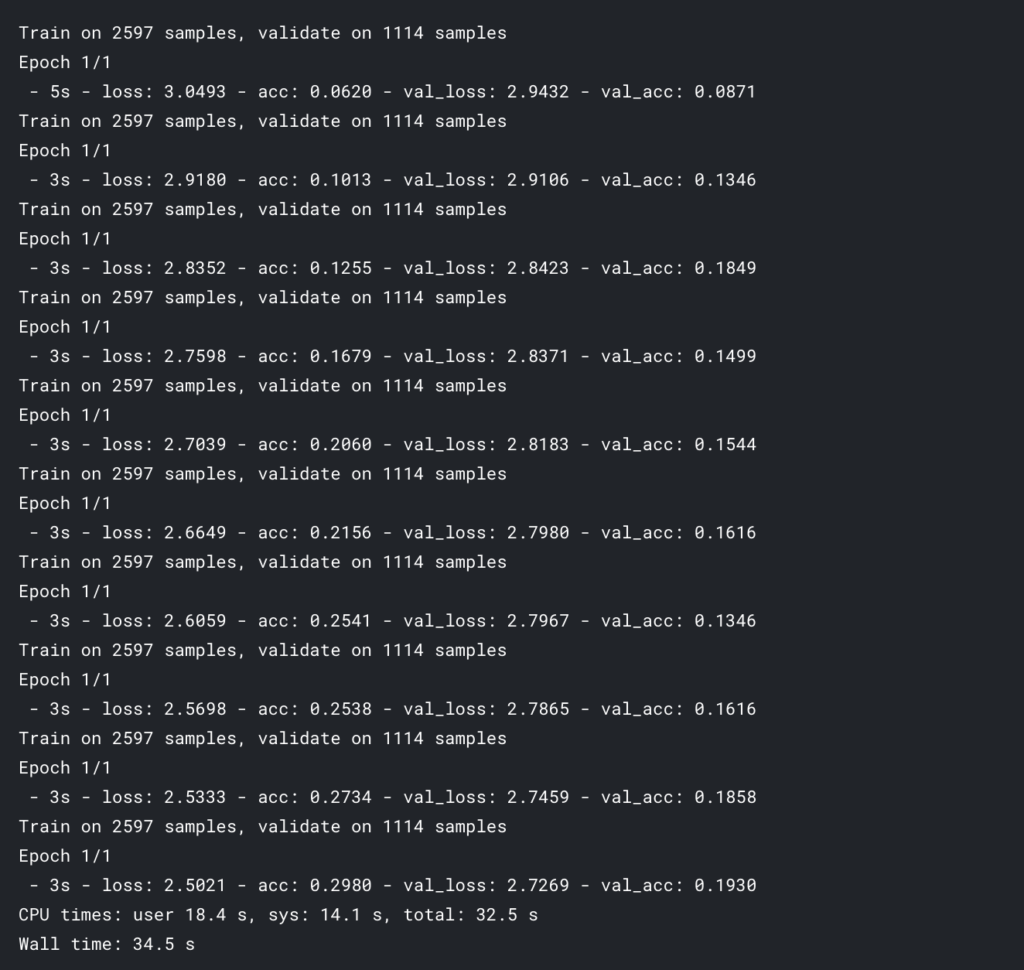
まだまだ学習できそうな雰囲気ですね。
というか学習できるんですね。
やはりアーティストによって、歌詞に使われる文章に傾向はあるみたいです。
歌詞は上記の通り、歌詞の1,000単語系列分を使って、長さが足りない部分は前ゼロパディングしています。
この系列長で、10エポック分を上記モデルで学習させて、34秒かかるみたいです。(カーネルのGPU利用)
バッチごとに系列長を調整する学習コード
さて、同じ問題を今度はバッチごとに系列長を調整して学習させてみます。
やりたいこととしては、MAX_LEN は固定して全データでそれよりも長い文章は切ってしまうとし、さらにバッチごとでは、系列データの長さの95%点の長さに切ってしまって、学習をさせます。
結果、全てが MAX_LEN の長さでエンコーダーに入力して学習させていたところを、 MAX_LEN まで必要のないバッチに関しては、無駄にゼロパディングが入っていた部分をカットしてエンコーダーに入力させられるようになります。
これをやるためには、以下のようにバッチイテレーターを作成する必要があります。
def batch_iter(X, y, batch_size, shuffle=True):
num_batches_per_epoch = int((len(X) - 1) / batch_size) + 1
def data_generator(X, y, batch_size, shuffle):
data_size = len(X)
while True:
# Shuffle the data at each epoch
if shuffle:
shuffle_indices = np.random.permutation(np.arange(data_size))
shuffled_X = X[shuffle_indices]
shuffled_y = y[shuffle_indices]
else:
shuffled_X = X
shuffled_y = y
for batch_num in range(num_batches_per_epoch):
start_index = batch_num * batch_size
end_index = min((batch_num + 1) * batch_size, data_size)
X = shuffled_X[start_index: end_index]
X = X[:, -int(np.percentile(np.sum(X != 0, axis=1), 95)):]
y = shuffled_y[start_index: end_index]
yield X, y
return num_batches_per_epoch, data_generator(X, y, batch_size, shuffle)
data_generator でバッチサイズ分のX,yを取得して返すようにしていますが、その途中、95%点の長さで切るというのを、
X = X[:, -int(np.percentile(np.sum(X != 0, axis=1), 95)):]
でやっています。
前にゼロパディングしているから、前から切っている点注意です。
Kerasの fit 関数では、適宜バッチサイズへの分割をしてくれますが、今回のように自分で作成したものを使う時は fit_generator 関数を使います。
学習のコードが以下。
model = build_model(embedding_matrix, n_class)
for global_epoch in range(EPOCHS):
train_steps, train_batches = batch_iter(X_train, y_train, BATCH_SIZE)
valid_steps, valid_batches = batch_iter(X_valid, y_valid, BATCH_SIZE)
model.fit_generator(
train_batches, train_steps, epochs=1, verbose=2,
validation_data=valid_batches, validation_steps=valid_steps,
callbacks=[LearningRateScheduler(lambda _: 1e-3 * (0.9 ** global_epoch))]
)
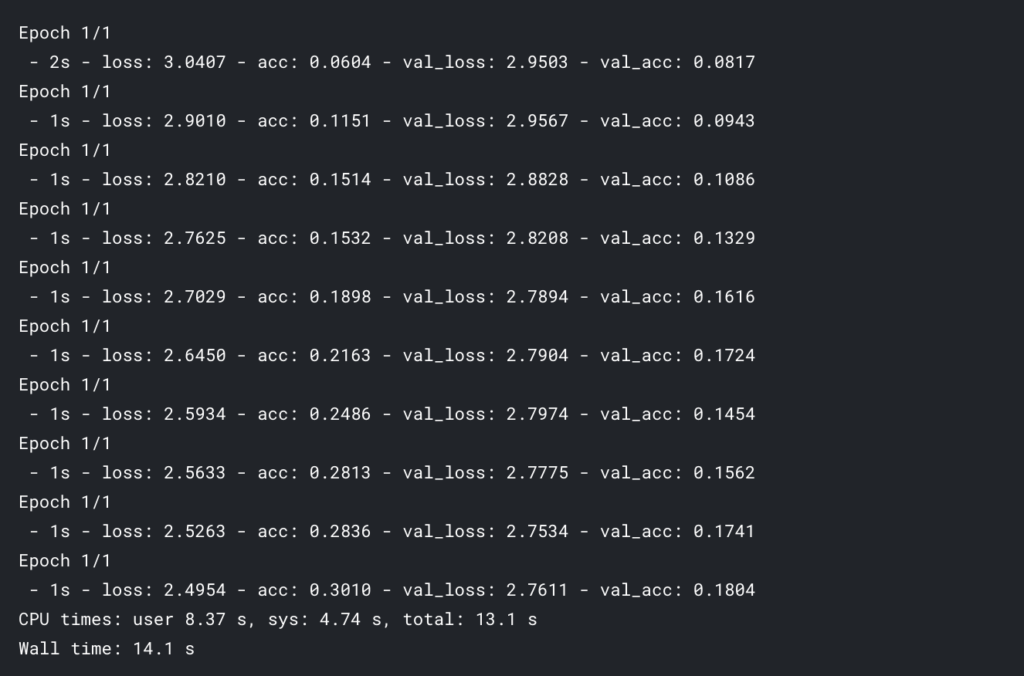
おお、はや。
ほぼ同じ精度を出しながら、普通に学習させた時の半分の速さでエポック数回すことができました。
概ね、ゼロパディング読み込みの有無の違いなだけな気はするものの、ここまで早くなるものなのか。
まとめ
バッチごとの系列長の調整のありなしでの学習速度の比較を行ってみました。
上記結果のように、精度を保ちながら学習速度を大幅に減らせることが確認できました。
実は最初は MAX_LEN も全データで一番長いものにしてしまって、それで比較できたらと思ったんですが、普通の学習の方がGPUメモリオーバーしてしまいました。(ですよねー)
なので、一番長いデータが含まれた状態のバッチがGPUメモリに乗るのなら、MAX_LEN を全データで一番長いものにしてしまって、系列情報を無駄なく食わせて学習させることもできるかもしれません。
コメント